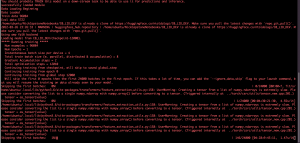
This week training began in earnest. The model was able to complete its first epoch of training in ~12hrs time. Preliminary values of its accuracy metric seem to show it sitting around 80% WER. This is not the ideal metric for this use case however, and after updating the metric I anticipate it to have a much better classification error rate. The outputs of the model so far have looked exceedingly reasonable so I feel good about it ability to be integrated with Marco’s model soon. Based on visual comparisons between golden transcriptions and predicted transcriptions, the model exclusively spits out M or E tokens for Mandarin or English respectively, never printing an ‘UNK’ character indicating confusion. I find this promising. For next week work will focus on continuing to train the model as well as integrating it with Marco’s work and exposing it for Tom’s work on web development. I feel that I am currently on schedule with the model’s progress. I may request additional limit allowances to speed up training but so far it would appear the data available is at least sufficient for basic language detection. I do not anticipate major blockages from here.