On Sunday, I met with Danielle and took videos of us demonstrating our system as she drove around Pittsburgh. Then, I made more changes to our Final presentation, polished my presentation script, and practiced for the Final presentation I gave on Monday. I am thankful that I memorized my script because, near the end of the live presentation, my computer froze over. I was not able to see the slides, but my audio was still working, so I presented completely from memory. I greatly appreciate my team for all their help in handling this technical difficulty!
After I presented, Heidi and I tackled our systemd bugs that we were facing the previous week. We wanted FocusEd to start as soon as the Jetson turned on, but the systemd service we tried to set up was giving us permission errors. Once we fixed one permission error, we were facing more issues related to the audio not playing. After much trial and error, we figured out our bug was related to the certain folder we were running in. Now, our system successfully runs on boot, making it a fully usable system. Heidi and I also worked to improve our FPS and delay, so now we run at 17+ FPS. We are still using 10W of power from our power bank and thus using 4 CPU cores (out of the 6 available). The latency improvements came from reducing the camera resolution.
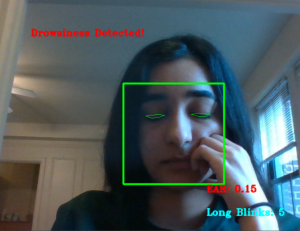
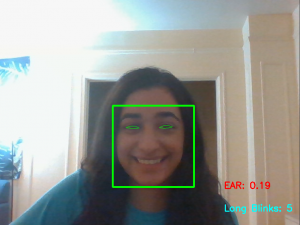
Afterwards, I took videos of myself using the faster system for our final demo video. This included screen recordings on the Jetson of our display with our eye landmarks and facial areas so that it is more clear what we are using to make our estimations.
I am on schedule and hope, in the next week, to help my team finish up our demo video and complete our final report.