Hello from Team *wave* Google!
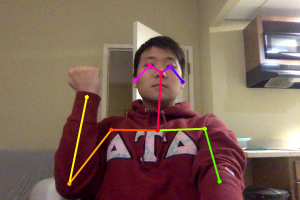
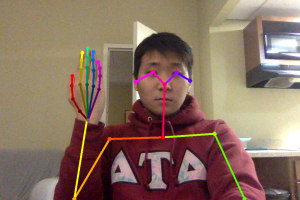
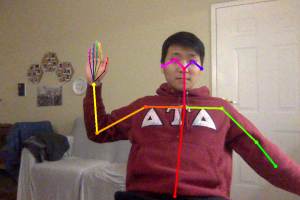
This week, we worked a lot on finalizing our idea/concepts in preparation for the design review. In terms of the gesture recognition software we were planning on using, we decided to use both OpenPose and OpenCV to mitigate the risk of misclassifying and/or not classifying at all. Initially, we were planning on only using OpenCV and have users wear a glove to track joints. However, we weren’t sure how reliable this would be so to mitigate the risk of misclassifying/not classifying, we added a backup, which is to run OpenPose to get joint locations, and to use that data to classify gestures. With this new approach, we will have OpenCV running on the nano and OpenPose running on AWS. Gestures in the form of video will be split into different frames, and those frames will be tracked with glove tracking on the Nano and OpenPose tracking on AWS. If we don’t get a classification on the Nano and OpenCV, we will use the result from AWS and OpenPose to classify our gestures.
We wanted to see how fast OpenPose could run as how fast we can classify gestures is a requirement we have, and on a MacBook Pro, we achieved a 0.5 fps with video and tracking one image took around 25-30 seconds. Now OpenPose on the MacBook Pro was running on a CPU, whereas it would run on a GPU on the Nvidia Jetson Nano. Even still, the fact that it ran 25-30 seconds on a CPU to track one image meant that it would be possible that OpenPose would not deliver our timing requirements. As such, we decided to use AWS to run OpenPose instead. This should mitigate the risk of classification being too slow by using OpenPose.
Another challenge we ran into was processing dynamic gestures. Processing dynamic gestures would mean that we would have to do video recognition to do our gesture recognition. We researched online and found that most video recognition algorithms rely on 3D-CNN’s to train/test because of the high accuracy that 3D-CNN provides compared to 2D-CNN. However, given that we need fast response/classification times, we decided not to do dynamic gestures as we thought they would be hard to implement with the time constraints that we are working with. Instead we decided to have a set of static gestures and only do recognition on those static gestures.
We’ve also modified our Gantt Chart to update the change in design choices, especially with the gesture recognition aspect of our project.
Next week, we are going to run OpenPose on AWS and start the feature extraction with the results we get from OpenPose tracking so that we can start training our model soon.