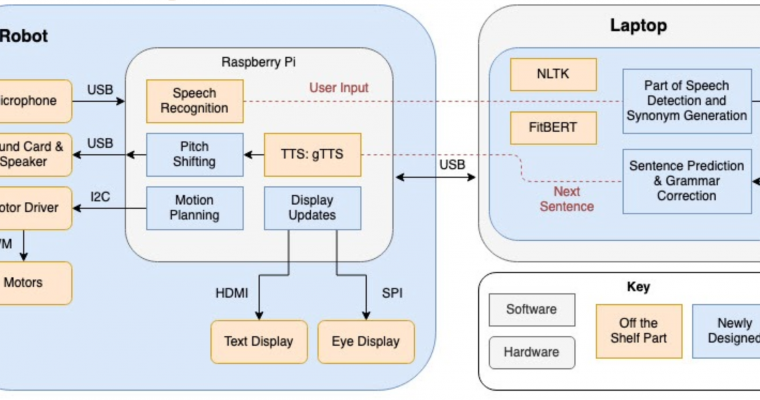
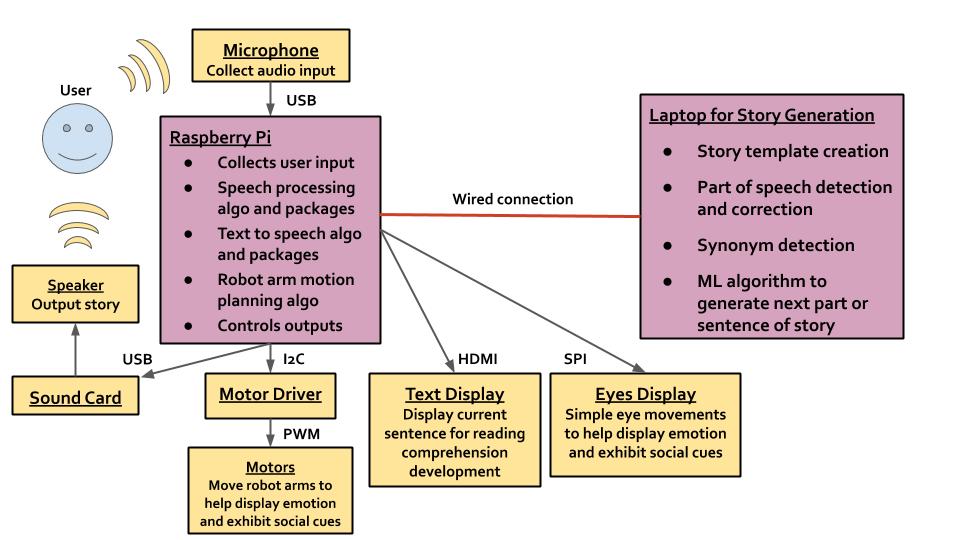
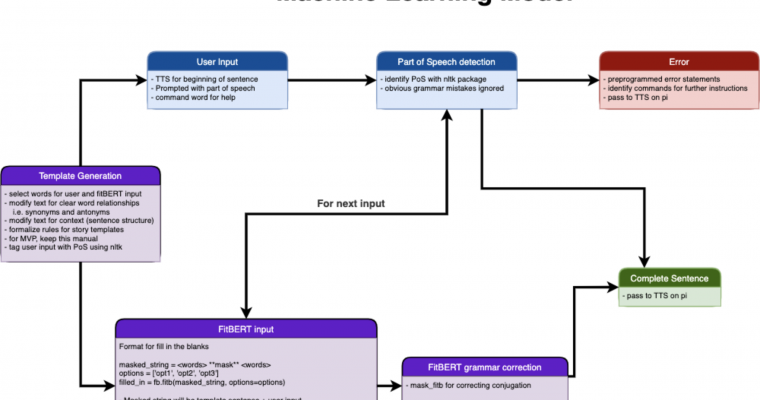
I spent the first part of this week editing and formatting the design report. Once that was finished, I started creating a user program for the storytelling algorithm. The user interface is command line at the moment, and this is how the program works:
- Program outputs start of sentence and part of speech of the user blank
- User inputs word
- Program fills in any related words
- Program finishes outputting the sentence and continues telling the story until the next user blank
Here is an example output for the user program (with the Nightingale template):

The program processes templates sentence by sentence, which is important for FitBERT input and keeps the output of the program as (sentence, POS) to pass on to the text to speech module. To work with this user program, I finished writing the FitBERT fill in the blank program, but I still have to implement grammar correction on both the user and algorithm side. On the user side, I have started implementing (but not yet finished) error detection on the user input, and I have integrated the user input processing with synonym generation to pass on to FitBERT.
Next week is spring break, which is not a part of our project gantt chart.
For the week after, I am hoping to finish error detection on the user input. I also have to implement a translation system between the parts of speech of NLTK and the parts of speech of our program because NLTK uses more specific parts of speech (like helping verbs and participles). I would also like to begin integrating the algorithm with the speech recognition module. Jade and I will work on getting the audio input captured by a laptop to the algorithm, and then getting the output sentence to the text to speech tool and saying the sentence.
If I have time, I am planning to finish the grammar correction part of the program, which should not take long because FitBERT is already set up and running, but I may have to push this till the week after.
I am still on schedule because I finished the fill in the blank portion quite early and will use the slack time to finish integrating all the programs I’ve written, which is taking a bit longer than anticipated. Once integration is done, I will circle back and work on improving synonym generation. Also, my portion is ready to begin integration, just as expected.