
The pitch contours are looking fairly good. I cleaned them further by trying to remove spurious troughs in the contour. I did this by taking max-series and then removing spurious peaks.
For improvement, I have been fine tuning the analysis. I have considered different options instead of just DTW:
For every alignment that looks really good, the autocorrelation would be completely symmetric, since the stretched function would look just like the one matched against it. So if I could instead get a measure of symmetry, or rather skewness, of the autocorrelation, this would show that for whatever amount of stretching needed (even if it were a lot), if it were very closely aligned then that would be the optimal match.
Besides the analysis, I have considered the complexity as well. Currently it matches within about 3 minutes for a 5 songs database, so this will need to be sped up completely. I am going to play around with the hop size for the DTW windowing. I have already bucketized the database contours and the query contours by about 0.1%, which seems to be the highest that still preserves information.
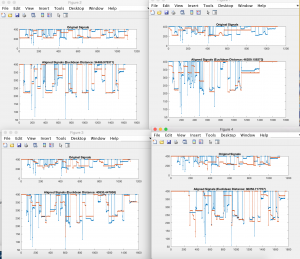
pictured above are some alignment plots. The blue is the sung query, and the contour of a song in the database at a segment in the song range that seemed to be the closest to what was sung.
Overall, I’m still going to be bumping up accuracy and complexity until the demo.