Team Status Report
Team B7: Chelsea Chen, Sandra Sajeev, Tian Zhao
Feb 23, 2019
Significant Risks and Contingency Plans
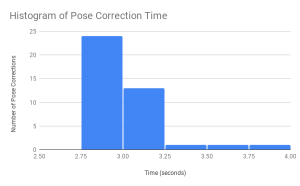
Risk: OpenPose does not always detect all necessary keypoints and sometimes even outputs inaccurate keypoints for a pose. Since our pose correction model relies on certain keypoints, the inaccurate results of OpenPose will trigger inappropriate instructions.
Plan: Since OpenPose frequently gives better estimation after we perform transformations such as flipping and rotation on the input image. we will try feed the transformed images together with the original image into OpenPose and take the best result among the outputs. Similarly, we can capture and feed OpenPose multiple images at once and see if OpenPose works well on any of these inputs.
This approach will likely improve the unstable performance of OpenPose, but also leads to worse runtime. We will need to find a balance between performance and runtime. Since OpenPose in general performs worse on certain rare poses, we plan to exclude these rare poses from our project.
Changes to Existing Design and Updates in Schedule
Change 1: In order to speedup the entire application, we have decided to use optical flow algorithm to trigger OpenPose computation. In this way, the program can achieve better runtime and thus give instructions more promptly. We have already refined the optical flow algorithm during the first few weeks, so no changes related to optical flow on our current schedule.
Change 2: We added calibration phase and priority analysis of verbal instructions to improve our previous design. Since we are currently a bit ahead of schedule, we will implement these two components in the following two weeks. We plan to have both basic calibration implementation (starting this week) and simple priority metrics of different instructions (starting next week) by Mar 6.
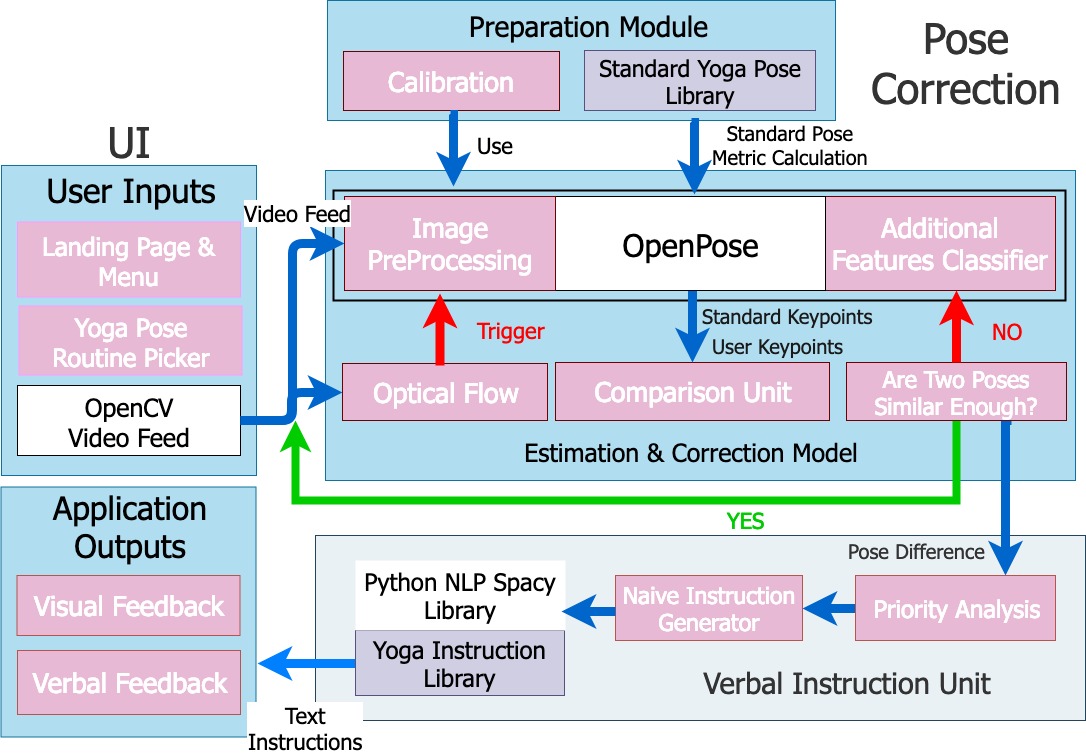
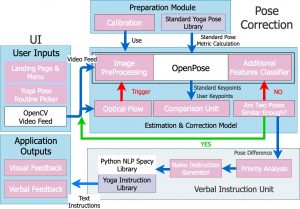
Updated Architecture Diagram:
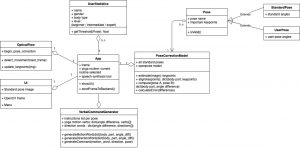
Individual Status Reports
Tian Zhao, Team B7
Accomplished Tasks
Task 1: Implemented the algorithm to calculate angle metrics for standard poses; Tested the algorithm on Tree Pose and Mountain Pose.
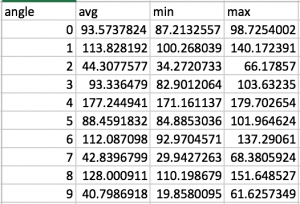
The angles were defined last week. For each pose, I tested images with OpenPose and chose a group of 7-10 images of yoga experts doing this pose. Then the algorithm calculated the average, min and max angles over these images. These angle metrics will be used in pose comparison as standards.
The angle metrics for tree pose are shown as follows. The upper image shows the output of the algorithm, angles 0~9 are RA~RE, LA~LE, respectively. The lower image is the keypoints on one of the sample image for reference.

Task 2 (with Sandra, Chelsea): Completed UML software design diagram for our software application. See attached diagram at the end of Team Status Report.
My progress is in general on schedule. After our meeting this Monday, we decided that Sandra would start testing the similarity method (Spacy library) for the verbal instruction unit. Instead I have implemented angle algorithms (Task 1) ahead of schedule.
Deliverables I hope to complete next week
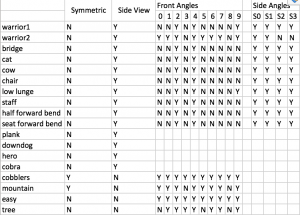
Deliverable 1: Construct Pose classes for 5 poses: Tree Pose, Mountain Pose and Warrior 1,2,3. These classes should at least include angle metrics, necessary keypoints to compute the differences and threshold for each angle for a user pose to be considered as “standard” (requires testing on webcam).
Deliverable 2: Implement algorithms that calculate differences between user pose and standard pose. For Tree Pose, integrate with verbal instruction unit and test on user inputs from webcam.
Sandra Sajeev, Team B7
Accomplished Tasks
This week, I worked with Tian and Chelsea to formulate our software design diagram. In addition, we designed a way to better improve the performance of optical flow. If a person is truly ready to undergo pose correction, then the idea is that we should have detected a large movement before hand. Thus, I implemented a flag to detect a large movement. It is only a combination of the active large movement flag and a period of little movement that can cause optical flow to trigger pose correction. I have done some simple unit testing to ensure this method works, but would like to begin on some more extensive testing soon. I also worked on developing new charts and graphics for our design review presentation. I have been practicing my speech for Monday.
Next, I worked on determining if the similarity verbal instruction method is viable based on spacy similarity module. I first collected a collection of sentences about Tree Pose from the site, Yoga Journal. Then I split the text into sentences and feed in the command “Move your right foot up”, because it is very common for people to place their right foot on their left knee during tree pose. The picture below demonstrates this phenomenon, with the skeleton on top depicting the correct range of motion.On first try, the sentence “Bend your right knee” produced the highest similarity result. However, after shortening the verbal commands from the internet, the sentence that had the highest similarity result was “Draw your right foot up and place the sole against the inner left thigh”, which represents the most accurate range of motion.

Deliverables I hope to complete next week
Thus, a good plan of action for next week, will be to expand and fine-tune the similarity method. This will include dynamically shortening the Yoga Journal verbal instructions when determining similarity. In addition, I would like to test the performance of similarity method for more yoga poses and commands, to determine if it is generalizable.
Chelsea Chen, Team B7
Accomplished Tasks
After more concrete discussions with my teammates this week, I completed the yoga instructions libraries for all the methods (naive method, similarity method, and template method). From simply gathering words and sentences for the libraries from yoga blog websites such as YogaJournal, I predict that the similarity method would work the best. Contrary to what we originally envisioned in the proposal phase – that instructions would mostly conform to the verb+body part+direction pattern, most instructions actually don’t conform to this pattern and a verb+body part+direction instruction would be really confusing to the users in most cases. These words and sentences in the libraries are currently only in a google doc document, but they will be coded into table entries in our python test program when we start the verbal instruction tests.
I also worked with Tian and Sandra to make the software design diagram.
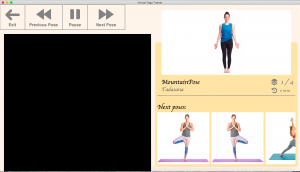
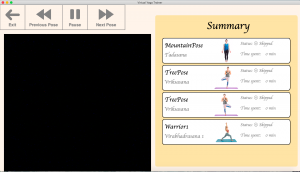
Lastly, I have started designing the aesthetic aspect of the UI component and below is a picture of the preliminary landing page. It has not been integrated with the frame-capturing video stream page, which I worked on in the previous few weeks.

Deliverables I hope to complete next week
As for verbal instruction, I think I will need to write up the testing code and collaborate with my teammates to test them. After testing the different methods, I hope to refine the definition of the best method’s library.
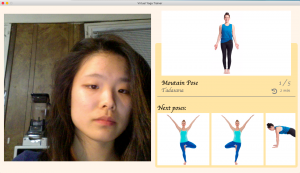
As for the UI part, I am a little behind on making the landing page as well as the OpenCV page. For the landing page, I will add more UI components. For the OpenCV page, I will construct a split screen that has the video stream as well as the image component side by side.