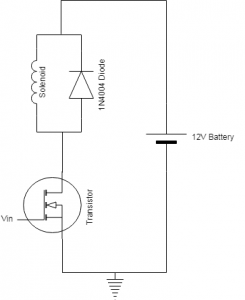
This week, I continued to flesh out the details for our machine learning algorithm. After looking at several other convolutional neural network architectures, I discovered that all of them consisted of at least one of each of these layers in a order like this: convolution -> ReLu -> max pooling -> dense -> softmax inference. Additionally, adding extra layers would often times increase the recognition accuracy, but increase the amount of time it takes to process one image. For our project, the sample space of possible images is small because our camera is stationary and will be focused on an area close to the ground. Therefore, inference will naturally be more accurate and not require a complicated neural network. To account for this, the neural network that we build will only have the one of each required layer of a convolutional neural network. If the accuracy of our deep learning algorithm does not hold up, then we will add an extra convolution layer and ReLu layer until it is accurate enough.
I spent the rest of my time determining valid success rate goal for our deep learning recognition. Our team had to figure out goals for false positives (raccoon is let in), and false negatives (your cat is locked out), but couldn’t justify our numbers. After much deliberation, our team decided to post polls on Reddit with questions such as “How frequently do unwanted animals invade your home every year?” or “How much money would you pay for a smart cat door which had a recognition rate of 95%?” Unfortunately, we had a very few number of responses, which doesn’t make the poll responses very useful. In the end, we decided that 95% would be a reasonable goal for our project. We will aim for at most 5% of false negatives and 5% of false positives.
Many research papers on animal recognition that we read reached on average a 95%-97% recognition rate (95% of the time, the algorithm correctly recognizes the animal), but were deployed in environments which were volatile. Because our environment is mostly static, our algorithm does not need to deal with edge cases, varying backgrounds, etc. Therefore, a 95% recognition rate is almost certainly achievable and is essentially the baseline that other deep learning algorithms have reached. Achieving something higher, such as 99%, could be done, but would require either algorithms which are much more advanced than we could implement, or adding other methods of detection like sound, heat, or weight.
Another controversial design decision that we made was to classify cats into breeds. Originally, we planned on doing something similar to cat facial detection, but we decided that doing something like that was out of our skill set. It is certainly possible to do cat facial detection – there are data sets online which have labeled features of cats (such as ears, eyes, fur, etc.). However, given the time frame of the project, we decided that the door will not be able to recognize your cat by its face, but will recognize your cat by its breed. The user will add his or her cat to the system and choose its breed from a list of breeds.
Lastly, I worked on finding data sets to train on. I found several data sets including images of dogs, cats, squirrels, raccoons, and human legs. These will be the primary objects that the camera will detect. Adding more classes of objects will be easy, since data sets are largely available online.