For this week, I began classifying the heart sound training data using a CNN. I researched that CNN’s aren’t very optimal to use for audio files so instead I am taking the spectograms of the data and then training the network on the images of spectograms rather than originally planned as the audio files. I also changed the architecture of the network to now include five convolutional layers that are each followed by a normalization and ReLU layer. The new architecture for my CNN in Matlab code is:
- convolution2dLayer
- batchNormalizationLayer
- reluLayer
- maxPooling2dLayer
- convolution2dLayer
- batchNormalizationLayer
- reluLayer
- maxPooling2dLayer
- convolution2dLayer
- batchNormalizationLayer
- reluLayer
- maxPooling2dLayer
- convolution2dLayer
- batchNormalizationLayer
- reluLayer
- convolution2dLayer
- batchNormalizationLayer
- reluLayer
- maxPooling2dLayer
- dropoutLayer
- fullyConnectedLayer
- softmaxLayer
- weightedClassificationLayer
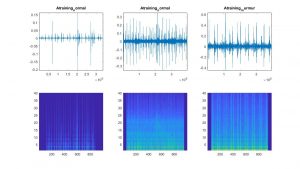
Here is also a visualization of example spectograms of both normal and abnormal heart sounds from the training data:
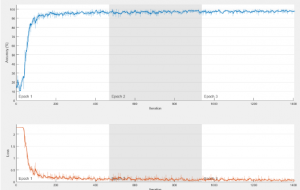
I then ran the CNN and it achieved an accuracy of 56.52% in 55 seconds to run. I ran it with 25 epochs.
Here is the graph of the training session:

Improvements have to be made to the preprocessing of the data as well as finding a more optimal architecture for this data in the next week.
I am currently on schedule for the week.