This week I worked on classifying the testing heart sound data as abnormal vs normal using a Convolutional Neural Network. The design for the CNN is as follows:

Since we are no longer using an external cloud service to run our analysis, I have to decrease the size of the data using MaxPool Layer, which transforms the original data file by ignoring the local minimum values and only extracting the maximum values in a local area. The ReLU layer is mainly used to make the data non-linear, but it also reduces the computation time because it sets all negative values to be zero and computations with values of zero are much easier on a system than doing computations on also negative values. This structure was successful for me when classifying images of handwritten digits, so I was curious whether it would also be successful for audio data. The input audio data for the neural network was the filtered training sound files from week 2. If unsuccessful, I have to either improve the filtering technique using Eri’s research or change the structure of the CNN.
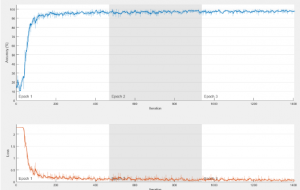
This is what the results looked like, but it never reached a final accuracy rating since it kept jumping around for the final iterations, so the structure of the CNN has to be changed for the next few weeks.
I am on schedule with the classification.