For this week, our main focus was improving our CNN since in the last few weeks we hit a bump at about 75% accuracy. With improvements in preprocessing it actually decreased the accuracy, so we had to explore other methods. First we added more audio data to train on since we weren’t training on the entire Physionet dataset yet. Also, we played around with the architecture by changing the number of channels in our last two convolutional layers. We are still using in total 5 convolutional layers with a filter size of three for each one, but in the last two convolutional layers, we switched the number of filters from 48 each to 24 and 12 respectively. Once we tested the CNN with these changes, we consistently achieved an accuracy of above 85% as shown by the image below.
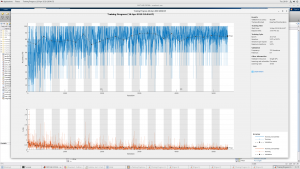
However once we tested again the next day, the CNN was consistently achieving an accuracy of above 80% but not always above 85%. Therefore, more testing has to be done to make the final leap above the 85%. We plan on testing with increasing the total number of filters that occur in each convolutional layer as well as increasing the number of epochs/batch size, although that will increase our training time significantly.
However, since our final demo is coming up, we are putting a hold on improving the CNN and have it communicate with the actual stethoscope to read real time data and classify the sound. Our team is meeting on Sunday to finish this task.