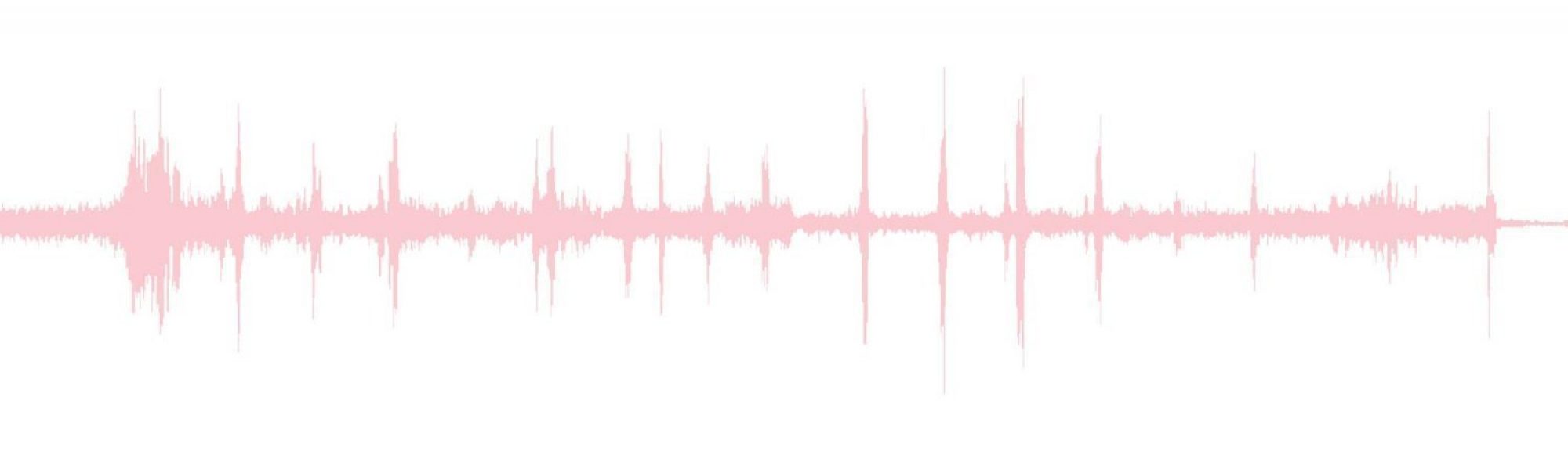
At the beginning of the week, Eri and I once again worked together on reducing noise of the heart sound test data. We first began by applying a band-pass filter to get rid of the higher and lower frequency noises that aren’t audible to a human ear (20 kHz). I’ve attached the original heart sound here:
Then here is the audio file after filtering out those frequencies:
As you can tell the background noise was reduced, so that the S1 and S2 beats are more audible and easier to analyze. We had an issue when there were sounds that were within the frequency caused by scuffling the mic, which we have to do further noise reduction or just eliminate those portions of the audio to analyze whether an abnormality exists.
I then decided to help designing the actual ML algorithm to classify the data because I’ve worked with Convolutional Neural Networks in my class and this would eliminate the need to segment the data because CNN’s are time shift invariant. The structure of my network is this:

I was able to achieve a 99.5% accuracy in classifiying images of handwritten digits, so I have to test the accuracy with audio files with this structure. I plan on testing this first thing tomorrow and will have number results in the next weekly update. Of course changes to this structure will have to occur to optimize the results for this dataset.
We are now on schedule because we were able to eliminate noise from the sound file as well as eliminate the need for segmentation of the heart sounds. We do want to test the accuracy of the segmentation and then classification through Support Vector Machines in the future to compare with these results.