One risk to take into account with the changed system design is the method of matching images taken from the camera with slides from the deck, particularly in edge cases such as animations on the slides where only part of the content is shown when the image is captured, or annotations on the slides (highlight, circles, underlines, drawing, etc.). Our contingency plan to mitigate this risk is having multiple different matching methods ready to try – we have the text extraction method which we will try first, as well as another CNN structure similar to how facial recognition works. In facial recognition, there is a “database” of known faces and an image of a new face that we want to recognize is first put through a CNN to get a face embedding. This embedding can then be compared to those of other people in the database and the most similar one is returned as the best match.
Another risk/challenge may be generating the graph descriptions so that they are descriptive yet concise; the success of the graph descriptions will depend on the reference descriptions that we provide, so our contingency plan is to each provide a description for each image we use during the training process so that we get less biased results (since each reference description will be weighted equally when calculating loss).
We made two main modifications to our project this week.
1. We added a graph description feature on top of our text extraction feature. This was mostly meant to add complexity, as well as help provide users with more information. This requires another separate ML model that we have to collect data for, train, and implement. This incurs the cost of increasing the amount of time it will take for us to collect data, since we were only previously expecting to collect data for slide recognition. However, we plan on mitigating these costs by finding a large chunk of the data online, as well as starting to create our own data as soon as possible, so we can get started early. This also feeds into our next modification, which is meant to help ease the burden of manufacturing our own data.
2. We modified our product to include a feature where the user should upload the slides to the app which their professor has made available before the lecture. Then, when the user takes a picture with our camera during class, our app will just compare the text on the picture the user has taken with the text on the pre-uploaded slides, and recognize which slide the professor is currently on. This is important because our product will extract both text and graph data with much better accuracy since we would be working directly off of the original formatted slides, rather than a potentially blurry and skewed image that the user would take with our fairly low resolution camera. This also decreases the latency, because now all of the text and graph descriptions can be extracted before the lecture even begins, so the only latency during the lecture will be related to determining which slide the user is on, and the text to speech — both of which should be fairly quick operations. This modification also allows us to scrape lots of the training data for our ML model from online: previously we would have to collect data of blurry or angled photographs of slides, but now that we’re working directly off of the original slides and graphs, we would only need pictures of the slides and graphs themselves, which should be easy to find ourselves (and create if needed). This does incur the extra cost of the user having to upload the slides beforehand, which raises accessibility concerns. However, we plan on including haptics and accessibility functions to the app that would make this very easy. It also incurs the cost of the professor having to upload the slides beforehand, but this is usually done regardless of our product’s existence, so we don’t think this is too big of a concern.
Here is our updated schedule, which is also included in the Design Presentation:

Here are some progress photos from this week:
Slide bounding box recognition:
Slide pre-processing:

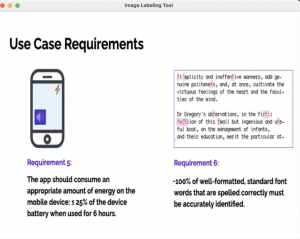
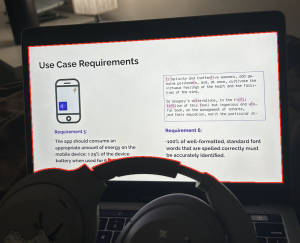
ML Data Tagging Tool: