
This week I worked mainly on the pre-processing of potential slide image data, as well as the post-processing of possible text outputs.
First, I took an image on my phone of my computer screen with a sample slide on it:
For the pre-processing, I first figured out how to de-skew the image and crop it so the existence of the keys on my computer keyboard wouldn’t affect the output:

However, I found that no amount of purely geometric de-skewing is going to perfectly capture the four corners of the slide, simply due to the fact that there could be obstructions, and the angle might be drastically different depending on where the user is sitting in the classroom. This led me to believe that we could use this deskewing as a preprocessing step, but we’ll likely need to build out an ML model to detect the exact coordinates of the four corners of the slide.
I tried using contour mapping to find a bounding box for the slide, but this didn’t work well when there were big obstructions (which definitely can be present in a classroom setting):
Here the contour is mapped in the red line. It seems okay, but the bottom left corner has been obstructed, and thus has shifted upwards a little. It would simply be a better solution to train a model to identify the slide coordinates.
I tried using combinations and variations of some functions used in image processing that I found online: blur, thresh, opening, grayscale, canny edge, etc. Eventually, I found that the best output was produced when applying a combination of grayscale, blur, thresh, and canny edge processing:

All of this produced the following output:
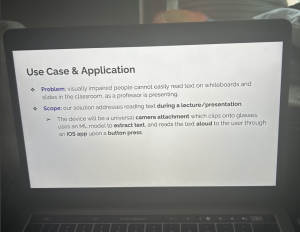
Use Case & Application & Problem: visually impaired paople cannet easily read text on whiteboards and Slides in the classroom, as a professer Is presenting.
® Scope: our solution addresses reading text during a lecture/presentation.= ‘The device will be a universal camera attachment which clips ento glasses, uses an ML medel to extract text, and reads the text aloud to the user through an OS app upon a button press.
So, I looked into post-processing methods using NLTK, Symspell, and TextBlob. After testing all three, NLTK’s autocorrect methods seemed to work the best, and provided this output:
Use Case & Application & Problem : visually impaired people cannot easily read text on whiteboards and Slides in the classroom , as a professor Is presenting . ® Scope : our solution addresses reading text during a lecture/presentation . = ‘ The device will be a universal camera attachment which clips into glasses , uses an ML model to extract text , and reads the text aloud to the user through an Of app upon a button press .
There were errors with respect to the bullet points and capitalization, but those can be easily filtered out. Other than that, the only two misspelled words are “Of” which should be “iOS” and “into” which should be “onto.”
After all of this processing, I used some ChatGPT help to write up a quick program (with Python’s Tkinter) that could help us tag the four corners of a slide by clicking on the edges, with a button that allows you to indicate whether an image contains a slide or not. The following JSON will be outputted, which we can then use as validation data to train our future model:
[
{
"image_file": "filename",
"slide_exists": false,
"bounding_box": null
},
{
"image_file": "filename",
"slide_exists": true,
"bounding_box": {
"top_left": [
48,
195
],
"top_right": [
745,
166
],
"bottom_right": [
722,
498
],
"bottom_left": [
95,
510
]
}
}
]
Outside of this, I worked on the design presentation with the rest of my team. I am ahead of schedule, since I did not expect to do so much of the pre/postprocessing work this week! I actually had meant to build out the app this week, but I will update the schedule to reflect this change, since the processing seemed the most valuable to do this week.
Next week, I plan to write a simple Swift app that can communicate with a local Flask server running on my laptop. The app should be able to take in an image, send the image to the Flask server, receive some dummy text data, and use text to speech to speak the text out loud. Since I don’t have experience developing apps, most of this code (at least for this test app) will be scraped from the internet, as well as through ChatGPT. However, I will make sure to understand everything I implement. I also plan to take lots of images of slides from a classroom so I can start tagging the data and training an ML model.
For my aspect of the design, I learned the NLP postprocessing methods when I worked on a research project in sophomore year to recognize the tones of students’ responses when asked questions through a survey. I learned the image processing methods through working on planar homography for a lunar rover for the course 16-861 Space Robotics this semester. I haven’t specifically learned iOS development before, but I learned Flutter for a project in high school, and familiarized myself with the basics of XCode and SwiftUI through GeeksForGeeks last week, and I will use the principles I learned in 17-437 Web App Development to develop it. I am planning on implementing HTTP protocol, and I learned this in 18-441 Computer Networks.