This week, our team presented our design review for the final vision of Awareables. I spent the beginning of the week under the weather, which meant that we met fewer times as a whole group.
Individiually, I spent some of the week experimenting with a pre-trained model that was trained on the 30,000 image set we intend to use for our model. I started by feeding the model the pre-processed images that Jay provided me with last week. Of the four different filter outputs, non-max suppression yielded the best accuracy, with 85% of the characters recognized accurately (Blur3: 60%, Orig: 80%, Thresh3: 60%). That said, non-max suppression may be the most processing-heavy pre-processing method, so we will have to weight the cost-benefit tradeoff there. Interestingly, most misidentified characters were misidentified as the letter “Q” (N, S, and T are all only some “flips” away from Q). Furthermore, “K” is likely to be misidentified if the two dots are not aligned to the left side of the image.

It’s clear that using any pre-trained model will be insufficient for our use-case requirements. This further justifies our design choices to: (1) train our own machine learning model (2) on a dataset modified to more closely resemble the output of our pre-processing pipeline. Therefore, I have also been taking some time to look at various online learning resources for machine learning and neural networks, since as a group, we have fairly little experience with the tools. My main question was how to choose the configuration of the hidden layers of a neural network. Some heuristics I have found are (1) hidden layer nodes should be close to sqrt(input layer nodes * output layer nodes) and (2) to keep on adding layers until test error does not improve any more.
Looking at the frameworks available, it seems most likely that I will be using Keras to configure a TensorFlow neural network, which, once trained, will be deployed on OpenCV. I will also take some time to experiment with decision trees and random forest on OpenCV using hand-picked features. Based on this and last week’s experience, it takes around 1-2 hours to train a model (20 epochs reaches an accuracy of 95+% against test dataset) locally with the equipment I have on-hand. We are looking into how to avoid waiting for model training as a blocker by using AWS SageMaker.
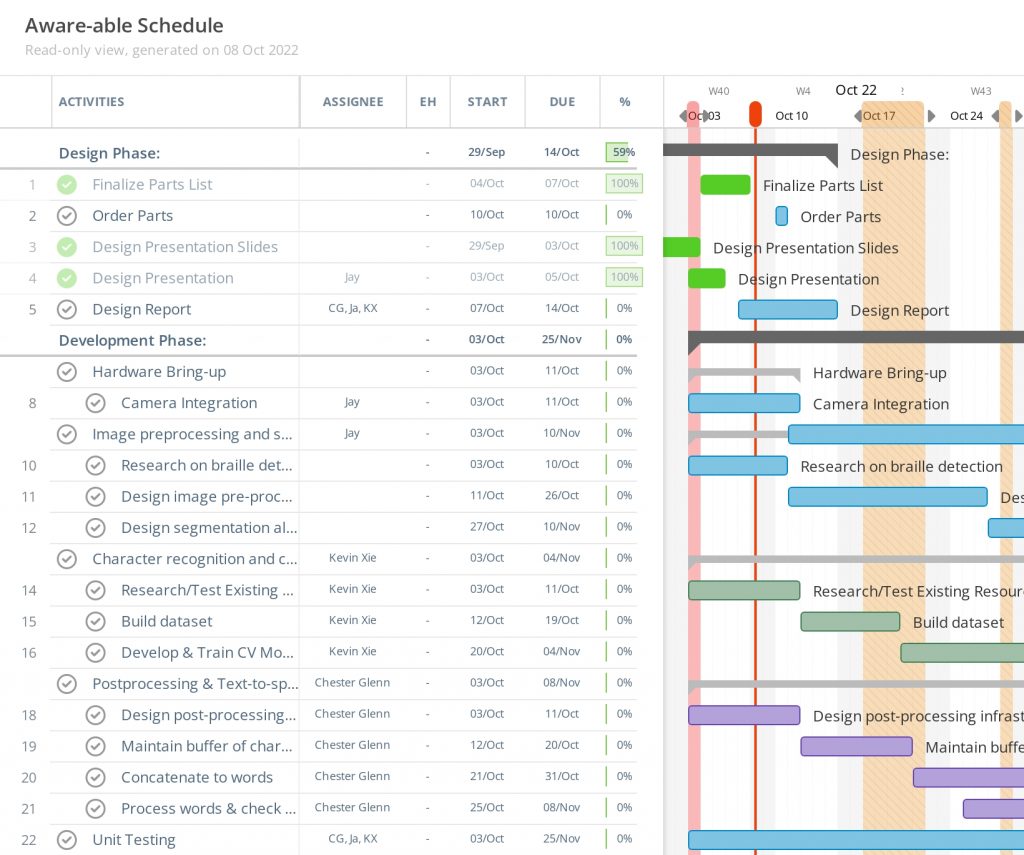
Looking at our Gantt chart, we are heading into the development phase following our design review. It seems like most, if not all, of us are slightly ahead of schedule for the time we have budgeted (due to running individual experiments as part of our design review).
Next week, I expect to be able to have set up an AWS SageMaker workflow for iteratively training and testing models, and have created a modified dataset we can use to train and test.