
Chester’s Status Report 12/10/2022
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
This week I spent the beginning portion preparing for my final presentation of our product and results. In addition, we continued to run validation testing on the integrated pipeline while smoothing out the bits and pieces. Overall, the post-processing segments are as solid as they need to be and we have really just been focusing on the entire integration.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
We are finishing up for the final demo and then the final report. Everything is looking clean and well integrated.
What deliverables do you hope to complete in the next week?
Last little touches are being put onto the project and then we will finish up the report!
Jong Woo’s Status Report for 12/10/2022
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours):
This week, all the clamps for our apparatus have been properly replaced with screws and glues. Final height adjustments for initial cropping have been tweaked correspondingly, and our team started crafting the final paper as well. Our team decided to create a poster to go along with the in-person demo, and I did some preps for the in-person demo presentation.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?:
Pre-processing has been fully implemented to its original scope.
What deliverables do you hope to complete in the next week?:
Final report will be completed along with the in-person demo.
Team Status Report for 12/10/2022
- What are the most significant risks that could jeopardize the success of the project?
- Pre-processing: Pre-processing is completed and meets all design requirements and also possesses an machine-learning based alternative with a longer latency.
- Classification: Classification is more-or-less complete and meeting the requirements set forth in our design review. We don’t foresee any risks in this subsystem
- Hardware/integration: We are still in the process of measuring latency of the entire system, but we know that we are within around 5 seconds on the AGX Xavier, which is a big improvement over the Nano. We will continue to measure and optimize the system, but we are at risk of compromising our latency requirement somewhat.
- Report: We are beginning to outline the contents of our report and video. It is too early to say if any risks jeopardize our timeline.
2. How are these risks being managed?
Nearly everything has been completed as planned.
3. What contingency plans are ready?
Post-Processing: At this point there are no necessary contingency plans with how everything is coming together.
4. Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
Since last week, we have been able to measure the performance of our system on the AGX Xavier, and have chosen to pivot back to the Xavier, as we had originally planned in our proposal and Design Review.
5. Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
This change was necessary to more capably meet our latency requirements in the classification subsystem, where we were able to perform inferences 7x faster. This also improved the overall latency of the system.
6. Provide an updated schedule if changes have occurred.
We are on schedule to present our solution at the final demo and make final measurements for our final report without making any schedule changes.
Kevin’s Status Report for 12/10/22
This week started with final presentations, for which I prepared slide content and updated graphics:
Following presentations, I continued to work on integration and was able to put all our software parts together and verify functionality on the AGX Xavier.
AGX Xavier
This week, I was able to get TensorRT working on the AGX Xavier by re-installing the correct distribution of onnxruntime from NVIDIA’s pre-built Jetson Zoo. I was also able to install drivers which enabled us to use a USB Wi-Fi dongle instead of being tethered by Ethernet. Once the Xavier was set up, I was able to measure inference performance for my classification dataset:
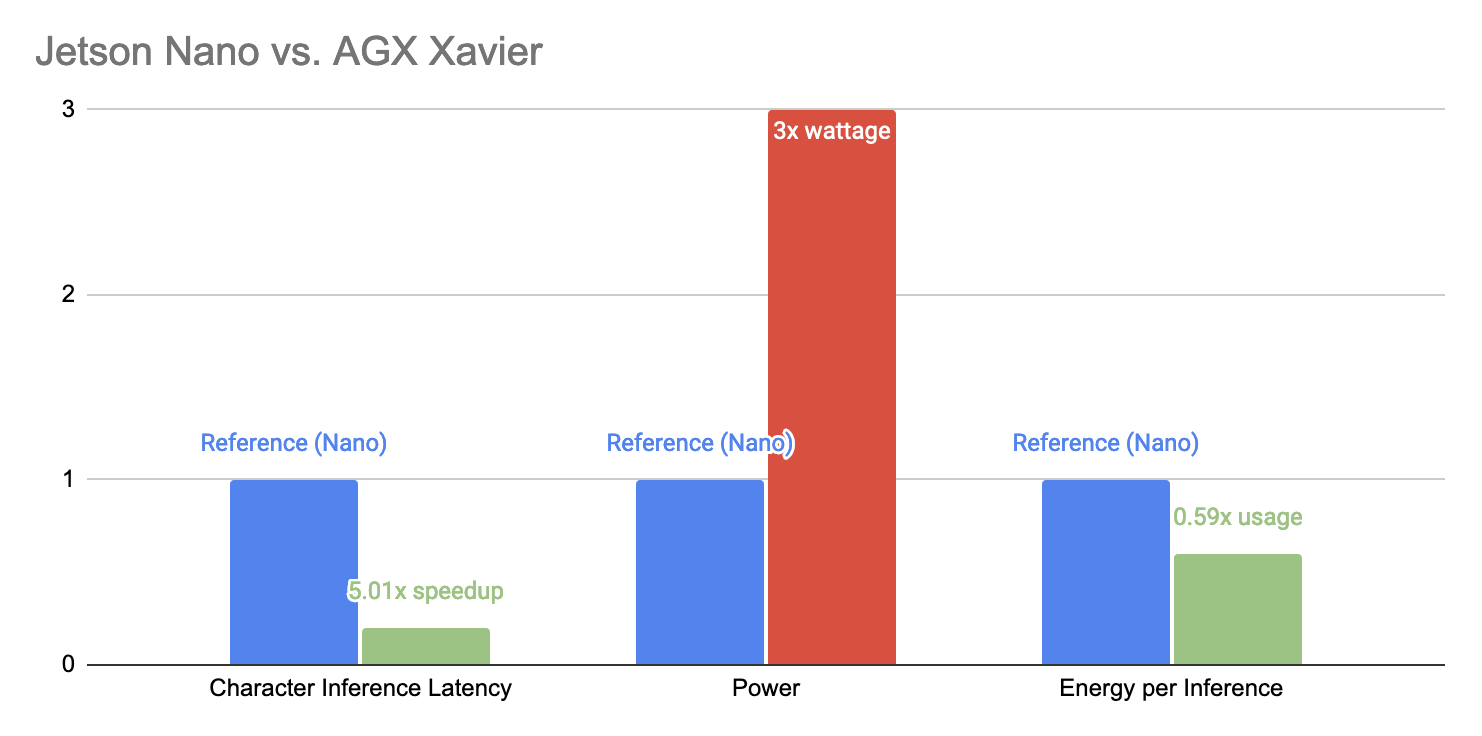
It quickly became clear that Xavier had a huge performance advantage over the Nano, and given our new stationary rescope, it seemed reasonable to pivot to the Xavier platform. Crucially, the Xavier provided more than 7x speedup over the Nano when running inferences with TensorRT. This meant that we could translate 625 characters in one second’s latency – more than 100 words – far exceeding our requirements. Combined with only 3x the maximum power draw, we felt that the trade-off favored the Xavier.
Integrating software subsystems was fairly straightforward once again, allowing me to perform some informal tests on the entire system. Using the modified AngelinaReader to perform real-time crops, we were able to achieve 3-5s latency from capture-to-read. Meanwhile, our own hardcoded crops / preprocessing pipeline was able to reach under 2s of latency, as we had hoped.
Experimental Feature: Finger Cursor
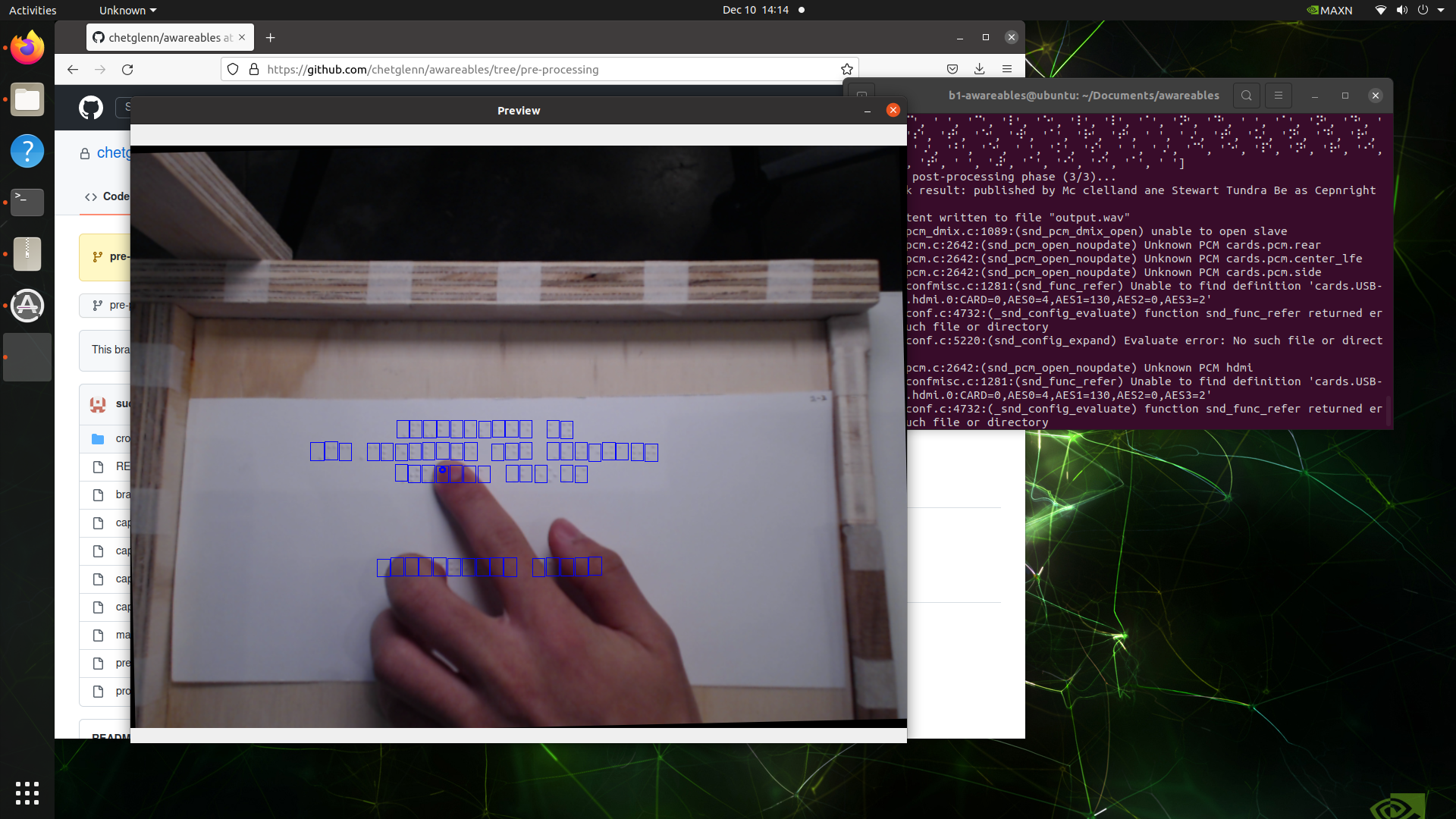
Because I had some extra time this week, I decided to implement an idea I had to address some of the ethical concerns that were raised regarding our project. Specifically, that users will become overreliant on the device and neglect learning braille on their own. To combat this, I implemented an experimental feature that allows the user to read character by character at their own pace as if they are reading the braille themselves.
Combining the bounding boxes I can extract from AngelinaReader and Google’s MediaPipe hand pose estimation model, I was able to prototype a feature that we can use during demo which allows users to learn braille characters as they move their fingers over them.
Using the live feed from the webcam, we can detect when the tip of a user’s index finger is within the bounding box of a character and read the associated predictions from the classification subsystem out loud. This represents a quick usability prototype to demonstrate the educational value of our solution.
Team Status Report for 12/03/22
What are the most significant risks that could jeopardize the success of the project?
- Pre-Processing: Currently, pre-processing has been fully implemented to its original scope.
- Classification: Classification has been able to achieve 99.8% accuracy on the dataset it was trained on (using a 85% training set, 5% validation set). One risk is that the model requires on average 0.0125s per character, but the average page of braille contains ~200 characters. This amounts to 2.5s of latency, which breaches our latency requirement. However, this requirement was written on the assumption that each image would have around 10 words (~60 characters), in which case latency would be around 0.8s.
- Post-Processing: The overall complexity of spellchecking is very vast, and part of the many tradeoffs that we have had to make for this project is the complexity v. efficiency dedication, as well as setting realistic expectations for the project in the time we are allocated. The main risk in this consideration would be oversimplifying in a way that might overlook certain errors that could put our final output at risk.
- Integration: The majority of our pipeline has been integrated on the Jetson Nano. As we have communicated well between members, calls between phases are working as expected. We have yet to measure the latency of the integrated software stack.
How are these risks being managed?
- Pre-Processing: Further accuracy adjustments are handled in the post-processing pipeline.
- Classification: We are experimenting with migrating back to the AGX Xavier, given our rescoping (below). This could give us a boost in performance such that even wordier pages can be translated under our latency requirement. Another option would be to experiment with making the input layer wider. Right now, our model accepts 10 characters at a time. It is unclear how sensitive latency is to this parameter.
- Post-Processing: One of the main ways to mitigate risks in this aspect is through thorough testing and analysis of results. By sending different forms of data through my pipeline specifically, I am seeing how the algorithm reacts to specific errors.
What contingency plans are ready?
- Classification: If we are unable to meet requirements for latency, we have a plan in place to move to AGX Xavier. The codebase has been tested and verified to be working as expected on the platform.
- Post-Processing: At this point there are no necessary contingency plans with how everything is coming together.
- Integration: If the latency of the integrated software stack exceeds our requirements, we are able to give ourselves more headroom by moving to the AGX Xavier. This was part of the plan early in the project, since we were not able to use the Xavier in the beginning of the semester.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
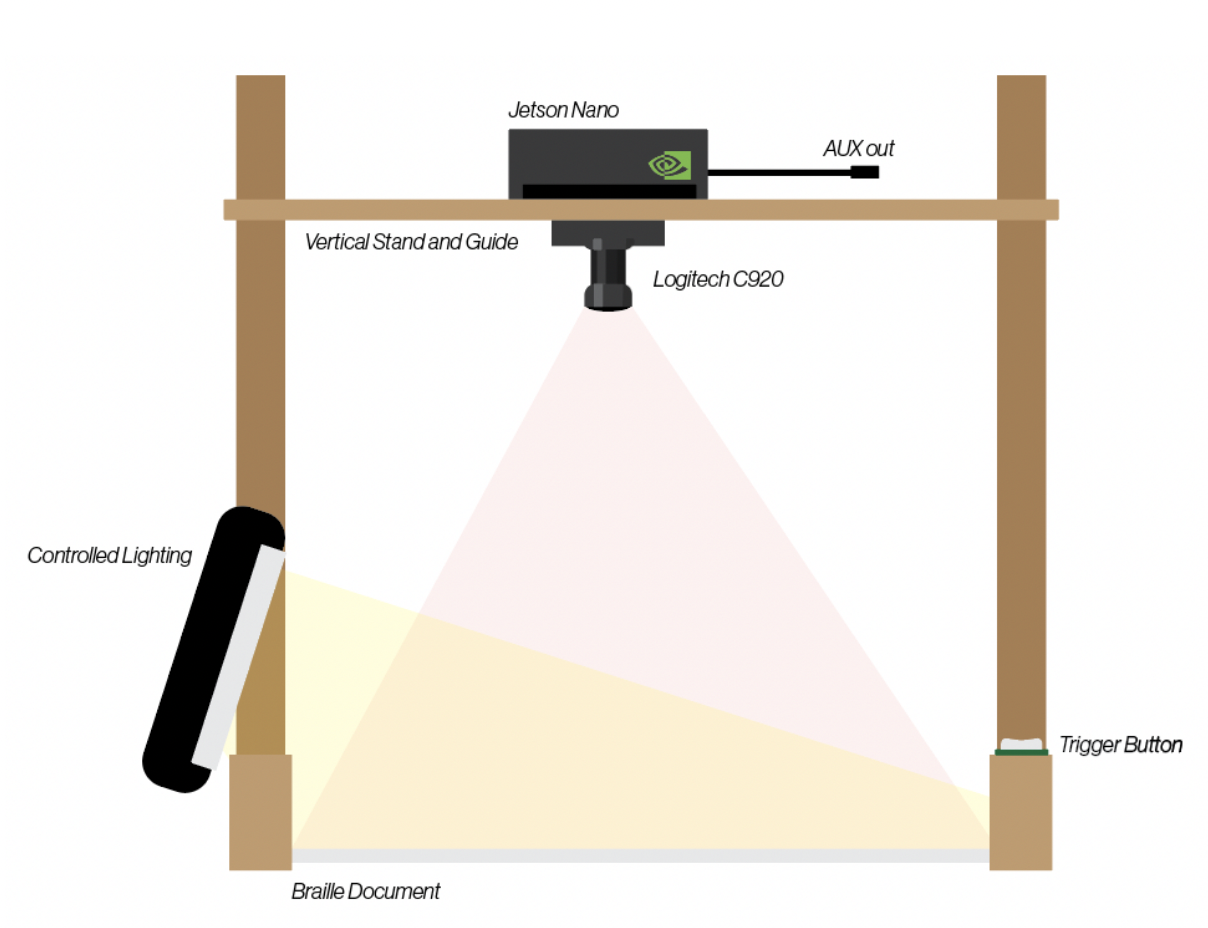
Based on our current progress, we have decided to re-scope the final design of our product to be more in line with our initial testing rig design. This would make our project a stationary appliance that would be fixed to a frame for public/educational use in libraries or classrooms.
Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
This change was necessary because we felt that the full wearable product would be too complex for processing, as well as a big push in terms of the time that we have left. While less flexible, we believe that this design is also more usable for the end user, since the user does not need to gauge how far they need to put the document from the camera.
Provide an updated schedule if changes have occurred.
Based on the changes made, we have extended integration testing and revisions until the public demo, giving us time to make sure our pipeline integrates as expected.
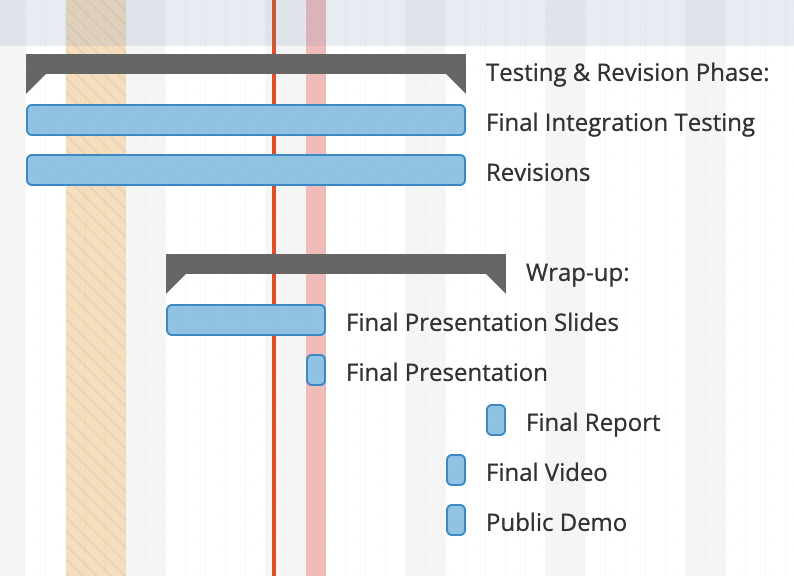
How have you rescoped from your original intention?
As mentioned above, we have decided to re-scope the final design of our product to be a stationary appliance, giving us control over distance and lighting. This setup was more favorable to our current progress and allows us to meet the majority of our requirements and make a better final demo without rushing major changes.
Jong Woo’s Status Report for 12/3/2022
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours):
This week, our team’s testing apparatus has been built in the TechSpark’s Woodshop and pre-processing has been fully implemented to its original scope. More specifically, further accuracy was attained through the non_maximum_suppression’s capability to locate individual coordinates and get rid of most of the pre-existing redundancies in green dots drawn on top. Therefore, when an image is taken, it is properly pre-processed, and then cropped to 150 ~ 800 individual braille images, and then handed over to the ML classification pipeline.




Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?:
Pre-processing has been fully implemented to its original scope.
What deliverables do you hope to complete in the next week?:
Final modifications and tweaking will be placed while prepping for the in-person demo.
Chester’s Status Report 12/03/2022
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
Overall a lot of progress was made this week in preparation for the final demo and presentation. We decided that rescoping our project away from natural scene braille detection and wearability was in our best interest. This is due to the complexity required for initial recognition.
In terms of the post processing section of the project, I was able to complete a significant amount of work in developing the spell checking algorithm even further. By taking in information about the projected confidence levels from kevin, I can check any number of characters throughout the string for corrections. After initial testing, this brings up the correctness to around 98-99% on single error words. In addition to confidence inclusions, I built a testing infrastructure that would run on large paragraphs of text and compare each word to a correct version after being run through the spell checker. For my algorithm, this gives me a clean interpretation of what is working best and what will work best after classification. I ran the test on both a static dictionary file with over 200,000 words, a text file containing sherlock holmes and little women with around 300,000 words, and a combination of both. The dictionary file provided the least accuracy due to the inability to produce a probability per word and limited size. The combination provided maximum confidence with very little efficiency loss. In addition, adding in the confidence matrix led to almost 2x speed ups for similar data sets. Of course these are simulated data sets so it will be interesting to run through the whole pipeline and see results.
In conclusion, we were also able to verify the sound capabilities of the jetson Nano and it was simple to connect to. This means that the full pipeline can perform on the jetson and we can run testing from pre-processing to post-processing.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
We are currently still on track after rescoping to the stationary educational model. I think it would have been nice to have more data for the presentation but overall I am happy with where we are.
What deliverables do you hope to complete in the next week?
As we get into the final stretch, I think it is crucial to be able to add final testing metrics and data for the presentation and final demo. This will show that we thoroughly checked our options and effectively came to our final product with quantitative reasoning.
Kevin’s Status Report for 12/03/22
Model Finalization
Since Thanksgiving break, having finally established a workflow for testing trained models against a large dataset, I was able to measure my model and tune hyperparameters based on the results. However, my measured results were shockingly poor compared to the reference pytorch implementation I was working with online. Despite this, I made efforts to keep training models by adjusting learning rate, dataset partitioning ratio (training/validation/testing), and network depth. I also retrained the reference implementation using braille labels rather than the English alphabet. Comparing results from 11 AWS-trained models using various parameters with this “fixed” reference implementation, it was clear that I was doing something wrong.
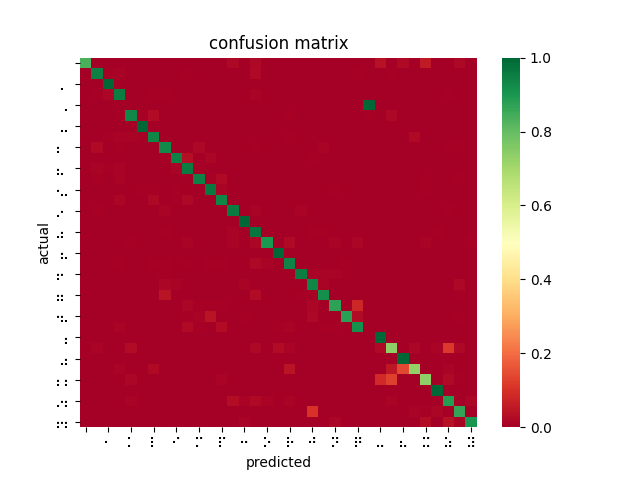
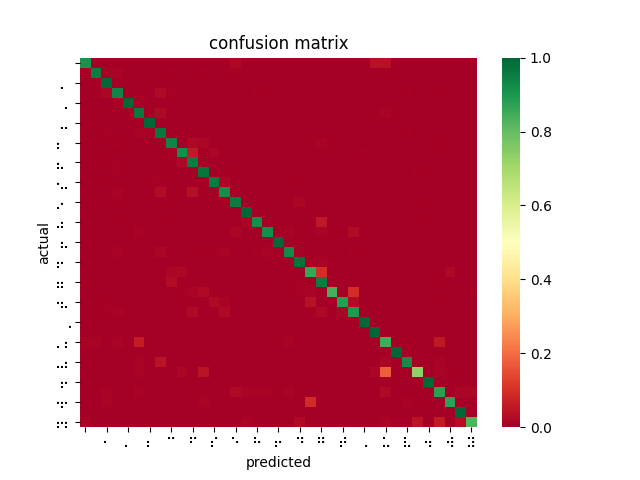
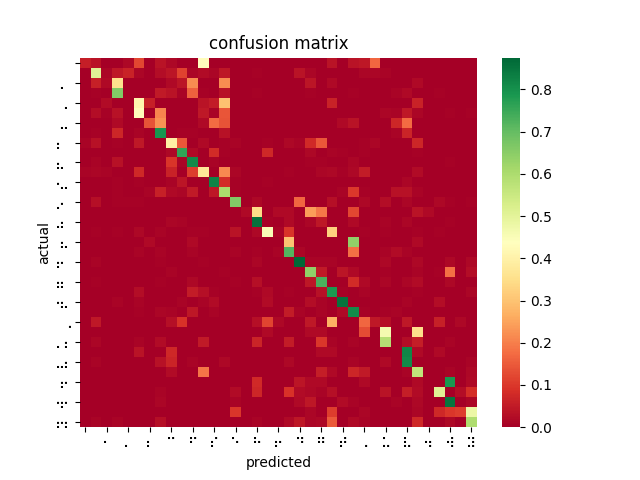
After poring over my code and re-examining the online documentation, I discovered that SageMaker’s image_shape parameter does not resize images as I was expecting and had been doing for inferences — instead, it performs a center crop if the input image is larger than the image_shape parameter. In fact, SageMaker offers no built-in function for resizing dataset images for input. This explains why braille symbols with more white space performed less favorably to denser braille symbols, and also why the model took longer to converge than I had seen described in related OCR papers. Modifying my testing harness to center crop rather than reshape, the models performed much better. However, it is not feasible to center crop all inputs since this would mean losing a lot of relevant data and likely using incorrect landmarks to overfit the classification problem. While wasting so much time and computation on invalid models was disappointing, I was able to upload a new dataset that was converted to 28×28 beforehand, and retrain a ResNet-18 on 85% of the dataset, yielding 99% accuracy on the dataset and 84% accuracy on the filtered dataset.
This is a far better result and greatly outperforms the reference implementation even when being trained on fewer images, as I had originally expected. I then performed 4-fold cross validation (trained 4 models on 75% of the dataset, each with an different “hold-out” set to test against). The average accuracy across all four trained models was 99.84%. This implies that the ResNet-18 model is learning and predicting rather than overfitting to its training set.
I also trained models using four different datasets/approaches: the original 20,000 image dataset; a pre-processed version of the original dataset (run through Jay’s filters); aeye’s curated dataset (embossed braille only); and transfer learning on a model that was previously trained on ImageNet.
Finally, I chose the two best models from the above testing and trained incrementally using the pre-processed/filtered dataset as a validation step to tailor it to our software stack. This greatly improved performance on a small batch of test crops provided to me by Jay.
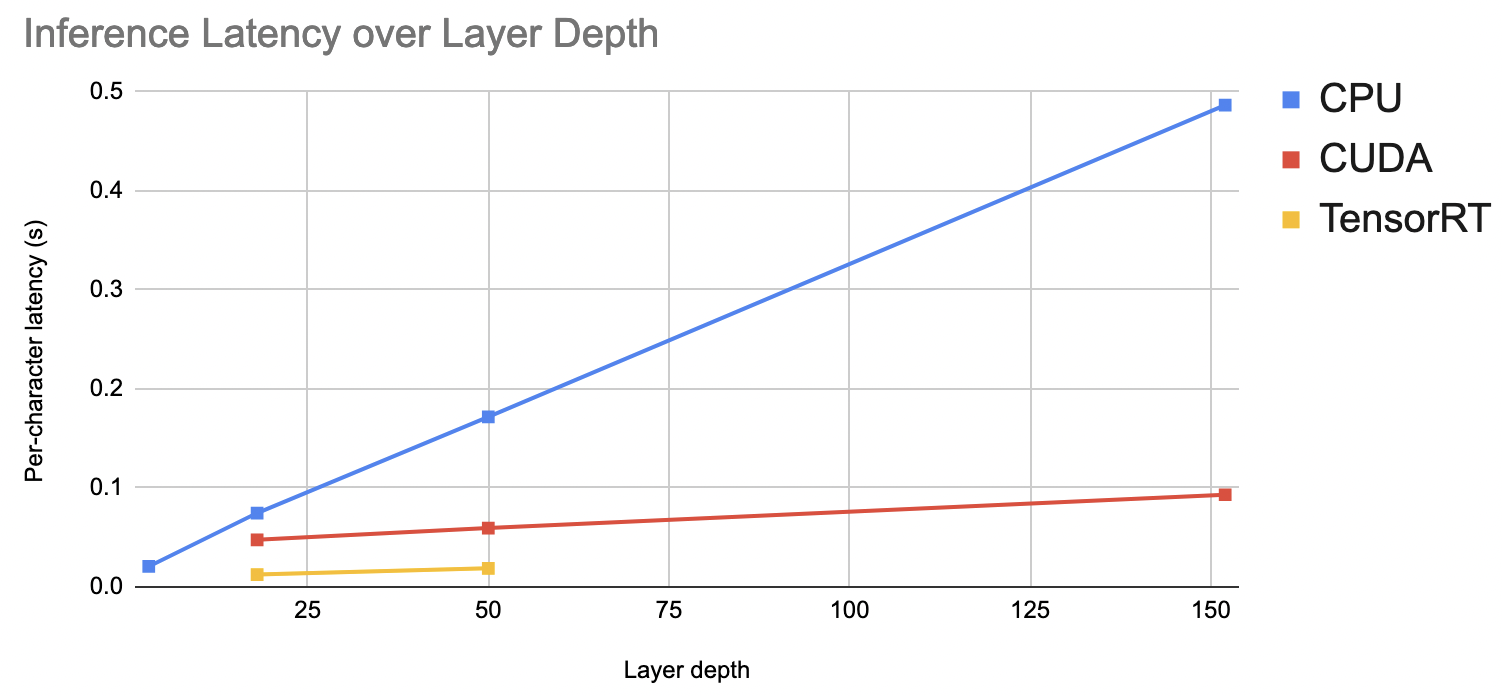
Finally, I was able to measure average per-character latency for a subset of models by running inferences on the Jetson Nano over a subset of the dataset, then averaging the total runtime. It became clear that layer depth was linearly related to per-character latency, even when increasing the number of images per inference. This is accelerated by using parallel platforms such as CUDA or TensorRT. As a result, our ResNet-18 on TensorRT managed to outperform the 3 convolutional block pretrained model on CPU (ResNet-152 failed due to lack of memory on the Jetson Nano).
Hardware
I was able to solder together the button trigger and program GPIO polling fairly quickly using a NVIDIA-provided embedded Jetson library. Integrating this function with capturing an image from a connected camera was also helped by third party code provided by JetsonHacks. I am also working on setting up the Nano such that we do not need a monitor to start our software stack. So far, I have been able to setup X11 forwarding and things seem to be working.
In addition, I have started setting up the AGX Xavier to gauge how much of a performance boost its hardware provides, and whether that’s worth the tradeoff in power efficiency and weight (since we’ve pivoted to a stationary device, this may not be as much of a concern). Importantly, we’ve measured that a given page has approximately 200-300 characters. At the current latency, this would amount to 2.5s, which exceeds our latency requirement (however, our latency requirement did assume each capture would contain 10 words per frame, which amounts to far fewer than 200 characters). I am, however, running into issues getting TensorRT working on the Xavier. It’s times like these I regret not thoroughly documenting every troubleshooting moment I run into.
Cropping Experiments
Having selected more-or-less a final model pending measurement, I was able to spend some time this week tinkering with other ideas for how we would “live interpret”/more reliably identify and crop braille. I began labeling a dataset for training YOLOv5 for braille character object detection, but given the number of characters per image, manual labeling did not produce enough data to reliably train a model.
While searching for solutions, I came across Ilya G. Ovodov‘s paper for using a modified RetinaNet for braille detection, as well as its accompanying open-source dataset/codebase. The program is able to detect and classify braille from an image fairly well. From this, I was able to adapt a function for cropping braille out of an image, then ran the cropped images through my classification model. The result was comparable to the RetinaNet being used alone.



AngelinaReader provides a rough training harness for creating a new model. It also references two datasets of 200+ training/validation images, combined. After making some modifications to address bugs introduced by package updates since the last commit and to change the training harness to classify all braille characters under a generalized class, I was able to set up an AWS EC2 machine to train a new RetinaNet for detecting and cropping Braille. Current attempts to train my own RetinaNet are somewhat successful, though the model seems to have trouble generalizing all braille characters into a single object class.


I trained two networks, one on the AngelinaDataset alone, and one on a combination of the AngelinaDataset and DSBI (double-sided braille image) dataset. After 500 epochs, I performed the opposite of Ovodov’s suggested method in the paper and moved the character classification contribution to 0 (we are generalizing braille characters) and trained the model for a further 3000 epochs. However, both implementations failed when given scaled images, unlike AngelinaReader’s pretrained model.


As a result, with so little time and having run out of AWS credits, we are considering adapting the pre-trained model for our pipeline (pending testing on the Jetson) and leaving room for fine tuning/training our own models in the future.
Jong Woo’s Status Report for 11/19/2022
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours):
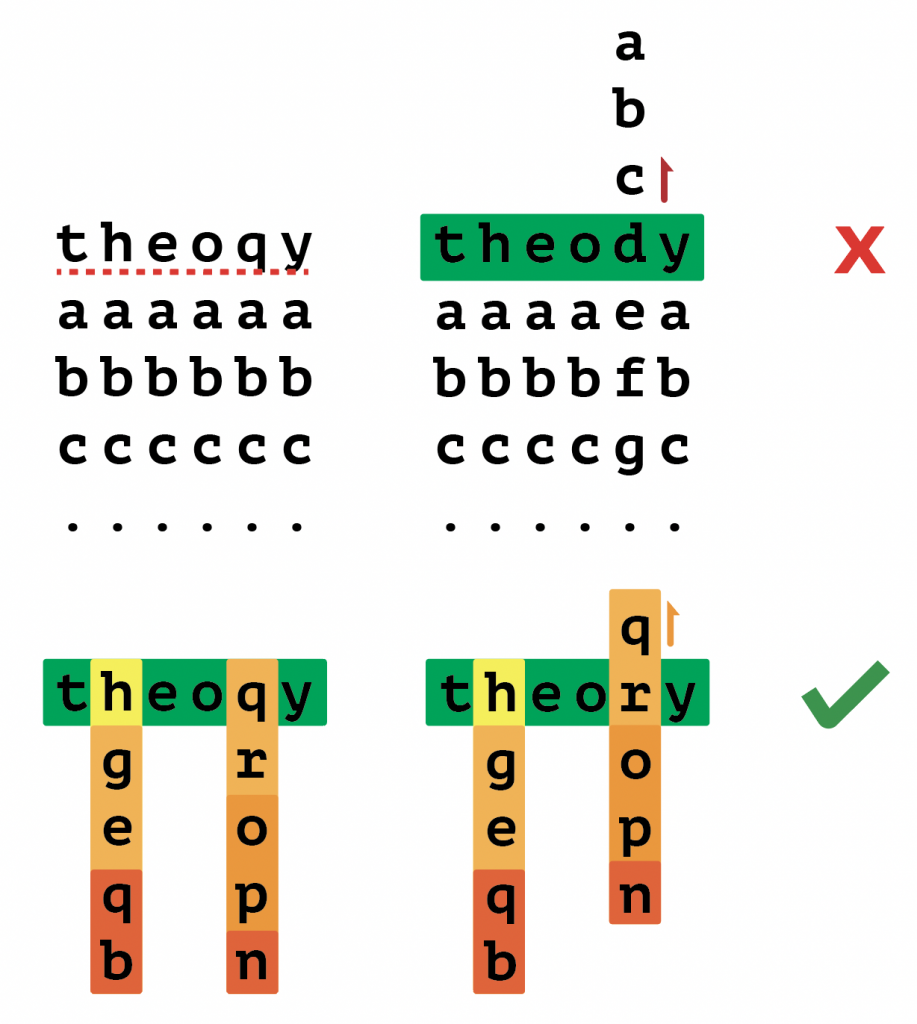
Currently ,I am primarily relying on the stats values (left, top coordinates of individual braille dots,as well as the width and height of the neighboring dots) from “cv2.connectedComponentsWithStats()” function. I have checked the exact pixel locations of the spitted out matrices and the original image and have confirmed that the values are in fact accurate. My current redundancies of dots come from the inevitable flaw of the connectedComponentsWithStats() function, and I need to get rid of the redundant dots sporadically distributed in nearby locations using the non_max_suppression. There is a little issue going on, and I do not want to write the whole function myself so I am looking for ways to fix this, but as long as this gets done, I am nearly done with the pre-processing procedures. Currently, I am looking more into how nms filter gets rid of redundant images and am planning on writing the nms filter function myself if it could not be debugged in time. I wasn’t able to make progress as of now (saturday) as far as the non_maximum_suppression filter is concerned, so further works are required tmrw in order to discuss some progress.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?:
The current, pre-defined non_max_suppression is currently not fully functional and am currently in the process of debugging to properly get rid of redundant dots. However, once this is taken care of, the pre-processing subsystem is nearly done so I am hoping to get it solved and done by thanksgiving-ish.
What deliverables do you hope to complete in the next week?:
The current non_max_suppression filter would either be tweaked or re-written to properly process redundant dots sporadically present near the target location. Furthermore, I have currently confirmed that the center coordinates of each braille dots as well as their corresponding width and height are accurate given the direct pixel-by-pixel comparison with the original image, so cropping should be completed with relative ease as well.