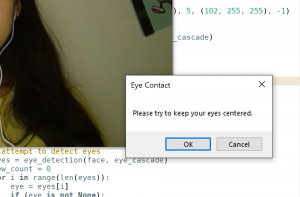
This week, I worked on combining the eye contact and screen alignment parts together for the facial detection portion, and implemented a way to store summaries about each video recording. I was able to integrate the eye contact part and the screen alignment part for option 1 to alert the user of both subpar eye contact and screen alignment. This required combining the two pieces of code I had written separately for options 2 and 3, so that there are setup phases for both eye detection and facial landmark detection, and that the coordinates of the center of the eyes and the nose/mouth were averaged during the initial 5 seconds. We then have separate frames of references for the eyes, nose, and mouth. In the respective parts of the code, if the current eye, nose, or mouth coordinates are off-center, the user is alerted of the appropriate one (eye contact or screen alignment).
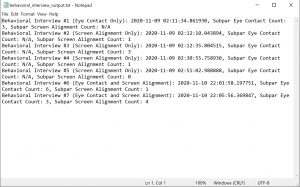
We were going to store the video recordings at the beginning of our project, and then allow users to view them in the profile section. However, we decided that it would be more helpful if we summarized the feedback from each video recording. There is a common text file (called behavioral_interview_output.txt) to store the video summaries. We calculate the interview number by counting the number of lines in the text file, and retrieve the timestamp of when the video practice took place using the Python datetime library. We keep track of the amount of times that the user had subpar eye contact and/or screen alignment during a video recording using count variables. The interview number, timestamp, subpar eye contact count, and subpar screen alignment count (for options 2 and 3, subpar screen alignment is “N/A” and subpar eye contact is “N/A,” respectively) are appended to the text file. This text file is to be displayed on the behavioral section of the profile page for the user to access.
I believe that we are making good progress for the facial detection portion, as we are wrapping up the technical portions and were able to accomplish a lot of the corresponding profile part as well. Next week, I plan on integrating the text file of the video recording summaries into Django for the web application. I also plan on continuing testing for the eye contact only option, and beginning testing for the screen alignment only option and the integrated eye contact and screen alignment option. I would like to get an idea of the current accuracy of the systems.