This week, the team continued researching and implementing their parts as laid out in the schedule and Gantt chart. The implementation of the project is spilt up into three main parts: facial detection, signal processing, and machine learning. Each team member is assigned to one of these parts and has been working on making progress with the relevant tasks. A change that was made to the overall design is that for facial detection, we are no longer going to be detecting posture, because there are too many unknown factors surrounding the task. There were ideas thrown around for “good” posture to be sitting up straight (e.g. distance between shoulders and face) or not having your head down (e.g. mouth is missing). However, if you have long hair, for instance, shoulder detection is not possible (and we cannot force a user to tie up their hair). Additionally, if your mouth is missing, then we will be unable to detect a face at all, which is another problem.
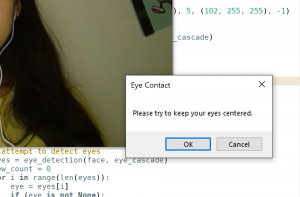
Jessica continued working on the facial detection portion, and was able to get the eye detection part from last week working in real-time with video. Now, when the script is run, OpenCV’s VideoCapture class is called to capture the frames of the video. The eye detection is then performed on each of these frames to attempt to detect the user’s face and eyes, and the irises/pupils within the eyes. A green circle is drawn around each iris/pupil to keep track of their locations. She is planning to get the off-center detection and initial set-up stage done next week, as well as start formally testing the eye detection.
Mohini started researching how to best represent the audio the user submits as a finite signal. Currently, she is able to save the audio as a finite matrix representing the amplitude of the signal, using the Nyquist Theorem. She is working on identifying patterns for different signals representing the same letter through analysis of the Fourier Transform. Additionally, Mohini reviewed her knowledge of neural networks and started working on the basic implementation of it. While she still has a significant amount of work to complete the algorithm and improve the accuracy, she got a good understanding of what needs to be done. She will continue to work and research both the signal processing and machine learning components of the project in the coming week.
Shilika continued to work on the web application website, questions databases, and the signal processing portion. She was able to complete the profile page and behavioral questions database. She made progress on the technical questions database and the signal processing or speech recognition. She hopes to have a first round of completed input for the neural network for speech recognition by next week.