
Michael – This week I was able to get the midi keyboard incorporated with the web app. A user can now record music using the midi keyboard and download that music as a midi file. The user can then upload that midi file and generate chords through the flow of the application. I also worked with Chris to improve the UI helping him to be able to display the chords as the song is being played as well as reduce some of the button clicking for a user. This week I will continue to test the application and make sure everything is as we desire in preparation for the demo.
Status update 11/25
Michael- Worked with Chris to update him and get him up to speed with how the webapp works and how to modify the user interface. I wrote a rest api endpoint for Chris to access chord data to display in user interface. I started working on incorporating the midi keyboard however did not have midi cables yet so I could not test the code. I plan on focusing on that the next couple days and believe I should be able to start testing our machine learning with midi keyboard input by Wednesday.
Chris – For the start of the week I spent some time getting myself familiar with the code base for the user interface part. Later I met with Micheal and worked with him to answer some of my questions and get myself up to speed. For the past week was Thanksgiving, I did not go too far on the code. In the coming week, my sole focus will be on implementing the user interface and I will keep updating the interface design as the functionality may change as time progresses.
Aayush – This week I finished processing the beatles dataset, with 19 songs available for the training set. I have also started collecting and processing songs for other artists, currently Tom Petty and Bryan Adams. Our predictions for tom petty songs are far better than compared to beatles songs, so collecting the training data is moving much faster. The current bottleneck is converting multi-track midi files to single track that contains only the melody, I plan to take Chris’ help with this part to speed up the process. The past week was mostly spent on manual work, and given that we have 194 songs in the original dataset, I believe we need at least a 100 parsed songs to effectively mix and match in order to create 3 final networks that we plan to demo. The total dataset will consist of –
- The wikifonia songs
- Beatles + Tom Petty + Brian Adams (50 songs / 2000 measures) (currently have 25)
- A third genre, probably more traditional rock such as RHCP, Deep Purple, Def Leopard. (50 songs / 2000 measures)
This week I plan to finish collecting songs in category 2, and train a new network with these songs. Since we already have the code in place to parse midi files, I need to work with Michael to integrate it so that it can be used in the training phase.
Status Update 11/18
Michael – The core functionality of our final webapp is working now. The user is able to upload a midi file without chords. The user is able to then generate chords and play the original and the melody with chords from the browser at the same time. The user can then download the file with chords at any time. Goals for this week include working with the midi keyboard and helping Chris incorporate what he has been doing into the application.Expanding the application to have multiple chord progressions once Aayush provides the multiple models will also be fairly trivial 
Chris – For the past week I have been working on the interface design for the web app, and I have got some pretty good results. After a few iterations of sketching and prototyping, I have landed on a visual structure and the corresponding color scheme. Improvements of the new design over the original design can be categorized into two aspects: the user experience and the visual. In terms of improvement on the user experience, I decided to break up the uploading interaction and the chord generation part into two interfaces because when user first land on our website, the interface should be a clear page with a description of what our web app does and a very clear call to action button (the Upload Melody button). The second improvement is dedicating the left part of the screen for clearer navigation. The content of the navigation menu is still to be decided as we add more/alter features of our product. In terms of visual, there are a number of changes, the most important of which are using blocks to create a more user-friendly visual hierarchy and displaying chord while the music is being played, which should be the central feature of our app. Other visual improvements include better color and typography choices to improve visual hierarchy, better organization of functional buttons, and more aesthetic rendering of the music. Finally, I also made a logo for our app. For the coming week, I will be working with Micheal to implement the design to the best degree. Some designs will be changed or dropped as always, and I will be continuing to improve the design as we go.
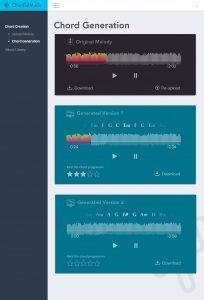
Aayush – I have been planning the final steps we need to take in order to prepare a test dataset for human evaluation. My initial goal was to use our chord prediction to ease the process of labelling the type of music we wanted (Beatle pop and rock). There were a few issues with Beatles songs that made this more difficult than anticipated:
- Beatles songs turned out to be far more complicated than I previously imagined, both in terms of chord changes and having more than one chord per bar.
- Songs often contain off-scale chords, which naturally makes prediction much tougher.
Nonetheless, we have managed to collect 20-25 single track Beatles melodies. I have processed 8 of these melodies (around 400 bars of music), 5 of which required major changes to our predicted output (> 60% of chords changed), while the other 3 required very minor changes (< 25% of chords changed) for a chord progression good enough to add to the training set. By changes I mean predicted chords I manually replaced.
Moreover, for non-simplistic melodies (usually characterized by a faster melody but not always), I noticed the output being extremely repetitive at random occasions, for example 4 C’s in a row where it should not have been. While training the data, I went for a less complicated model because test accuracy would not increase with model complexity. However, as I mentioned earlier, the predicted chords were much more varied with increasing model complexity. (For any complexity, the graph was almost identical except the number of epochs required to train)
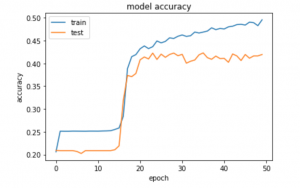
We were always aware that accuracy was a poor measure, yet defining another loss function seemed impractical given the lack of any good measure for test predictions. To tackle these issues, I think the following strategy would be most effective –
- Add modern pop songs to our dataset, which have much simpler chords. My aim is to have this as the vast majority of the dataset, so the network prefers simplistic output. The addition of songs form the wikifonia dataset and our collection of beatles songs can help add a small tendency for the network to take risks.
- Retune the network from scratch after accumulating the final dataset. It took me a long time, thorough testing, and detailed analysis of the output scores to finally realize the above issues with the network, implying the baseline model produced fairly pleasant sounds for the most part.
I will continue to test, fix predictions, and accumulate valuable training data for the rest of the week. With the evaluation looming I also chalked out a rough plan for the testing phase. For both the rating test and the confusion matrix –
- 5 curated songs where our network performs well. ( 2 of the Beatles songs could be used here, but I fell the retrained network can perform much better)
- 5 random songs chosen from our collection of pop songs.
- 5 composed melodies, not taken from original songs.
We will also collect data separately about which of the 3 groups performed best and worst.
Status Update 11/5
Michael- Aayush and I spent a lot of time working on integrating the machine learning with the webapp. This raised a lot of unexpected issues getting code to compile with because of certain dependencies which was very frustrating. Right now the web app is able to run on Aayush’s computer with no issues. The webapp currently takes in a midi file and outputs a midi file with the added appropriate chords based on machine learning algorithm. I also fixed a bug with the output of the chords and making sure each chord falls exactly at the start of each measure. My goals for next week include working more on the user interface such as being able to play the chords added midi file in the browser. Aayush and I have also talked about adding a feature in which you can see the different probabilities for different chords for each measure and being able to select which chord you would like from the browser.
Aayush = Worked with Michael on integration of webapp and machine learning. We still need to add a couple things to the webapp before the demo, such as handling time signatures and integrating the key recognition chris worked on (this part is nearly done). My focus this week will be to help michael implement the feature described above. The goal is to reduce the input set to a small number of possible chords. We believe the algorithm does this reasonably. We can then add songs, play the midi, tweak the chords if they don’t sound right. If we like the result we can then save the labels and the input. This way we plan to make many datasets, including separating by genres and separating by person (i.e. a model trained by only one person in the group), so that we can incorporate individual musical taste as well. We can measure if there are any differences in the output of models trained by different users on the same songs, and see if this is a direction worth pursuing. Similar strategy with genres, which we will start with first as per the initial plan which was also strongly suggested by the professors.
Chris – This week I worked with Michael to incorporate the key recognition part that I have been working on with the web app he has been working on. The bulk of work was focused on feeding data with the right format that’s parsed from the MIDI input to the key recognition module which is implemented with the MIT Music21 library. One thing that we had to deal with was that for the machine learning part, the input data format for each measure is the frequency of each note in the measure, regardless of which note comes first. However, for the key recognition to work properly, the sequence of notes is necessary. For the coming week, I will be working with Michael on the front-end of the web app in a few different areas, the first being improving the UI/UX of the overall web app experience, hiding the technical details that might not be very useful to the users. The second task is to implement the rating and evaluation part of the interface.
Status Update 10/28
Michael- Fixed problem where could only parse midi file from local file system. Now I have flow of application working so that I can upload a midi file, and a midi file with generated chords combined will then be downloaded for the user. This is important as we can now test our machine learning algorithm more quickly and easily and will work this we to see how we are for the midpoint demo. I will also continue to work on making the flow of the application better as right now it is in a pretty bare minimum state. The user just receives an updated midi file with chords. I would like to better incorporate the javascript midi player with the midi files we generate.
Chris – Last week I started working on a key finding algorithm and doing researches in this area. This week I evaluated the two approached I could take: machine learning and algorithmic, and decided to go with the latter for the season that it is more practical in terms of both time and efforts. I researched a few existing libraries and decided to proceed with Music21, one developed by MIT. The key finding algorithm, the Krumhansl Schmuckler algorithm is based on a statistical modal, which calculates the probability of any melody being in any key. Usually, the key with the highest likelihood is then selected. While this algorithm cannot guarantee a 100% accuracy, it is well enough for the purpose of our project. I Learned about using the module, or more specifically, I understood the concept of note and stream in music21, and how to apply them in the key finding algorithm. For the coming Monday, I will work with Michael on his data parsing part as some classes he wrote earlier may not be compatible with music21. Then I will incorporate the Krumhansl Schmuckler algorithm in our code.
Aayush – managed to get reasonable results from processing simple midi files. Working on identifying datasets that can give us the best results.
Status Update 10/21
Michael- Finished an algorithm to parse midi files to format useable by machine learning algorithm. It currently only works with type-0 midi files which is one track. This is not a bad assumption for our use case for now since we are focused on a melody and not multiple instruments at once. However other type midi files can typically be transposed in the future if need be. Used the mido library for the current algorithm. However was having some difficulties with inconsistencies between midi files and looked into mingus and LilyPond library to convert to a sheet music object and then parse. Ended up being able to figure out the parsing with mido so this is not needed at the time. For next week I want to work on the output algorithm going from machine learning output back to midi file and then incorporating with webapp.
Chris – This week has been a really busy one for me, just spent another weekend in New York for an interview; please pardon me for my lateness in making this post. My main task for the past week, and for the coming week as well is to figure out how to algorithmically decide the key, or in another word, the scale of a melody. This is crucial because the assumption we made for our main machine learning model is that all input melodies are already transposed to Cmaj key, which requires us to find the key of the melody in the first place. Although some MIDI file comes with the key in the metadata, we cannot guarantee that it is the case for all customized user inputs. I spent the majority of the time the past week researching the background of music key determinization, and it turns out to be much more complicated than originally expected. There are two popular approaches, the first one being the Krumhansl-Schmuckler key-finding algorithm (http://rnhart.net/articles/key-finding/), which is a statistical approach, and the other being a machine learning approach (https://arxiv.org/pdf/1706.02921.pdf). I have been researching both methods and evaluating which one is suitable for our project in terms of time, scale, and feasibility.
Aayush – got the lstm to predict chords, they are fairly reasonable from a music theoretic viewpoint, i.e. the notes in each bar generally correspond to the notes of the chord. Very limited testing has been done though, will now work on evaluation and testing different features/output prediction formats. Will then move onto dataset curation and hyperparameter tuning subject to results
Weekly Status Update 10/15
Michael-Spent the bulk of this week working on the design presentation and design paper. For this coming week, the goal is to have the web app working all the way up to being in the correct format to input into the machine learning algorithm. This involves sending file from javascript to python backend and then parsing it into the proper format.
Aayush – Spent this week trying out the ML Model to create an MVP for the chord prediction. Manually chose some songs in the C major scale and used these to train the network. The results were encouraging, so for the next week, I plan to generalize my parsing framework for the Wikifonia dataset (since for now there are certain hardcoded variables). I will try to train the model with all songs, and then filter songs that have complicated chords (suspended chords, uncommon modifications etc), and then compare results. The hope is to get an MVP that can then be used to label popular songs based on our ratings of the system.
Chirs – Most of my week last was spent preparing for the design presentation, and writing the design paper. For the past week, I also spent a decent amount of time studying the BLSTM model libraries and some existing code. In the coming week, I will work with Aayush to try to achieve an MVP which we can use our current dataset to train on and to get the model working for data input of four measures.
Weekly Status Update 10/6
Michael – Continued to work on programming the web application. Can successfully load and play a midi file. Still working on being able to send the midi file from javascript to python. My goal for the coming week is to work on the design documents firstly and make sure I understand all the libraries need for processing the midi files.
Chris – For the past week I took a deeper dive into the machine learning algorithm. I was mainly looking at the BLSTM and HMM. Additionally, I looked into how to use Keras, a Python machine learning library to set up the BLSTM algorithm. For the coming week, my goal is to work with Aayush to get the machine learning algorithm going to a point that we can feed the test music data in and get some reasonable output. On the side, for the past week, I also spent some time looking at some music theory documents to understand the mechanism behind how chords and melody work together. This way when we have the test ready and going, I will be able to evaluate, music-theory-wise, of the quality of our chord outputs, instead of just listening to them and judging by ear.
Aayush – I have been working on machine learning tests. I found a model here (https://github.com/luggroo/230-melody-to-chords) that used lstm’s and Gated Recurrent Units (GRU’s) for chord generation, however when we reproduced their results, they was quite poor, mostly due to lack of data. With the help of this code however, I was able to identify changes we would need to make to process the wikifonia dataset, and to implement the design proposed in the presentation in Keras. This includes adding the bidirectional layer (well supported in keras) and zero padding to handle songs of varying length. Working this week on the design presentation, followed by implementing the model in https://arxiv.org/pdf/1712.01011.pdf using the wikifonia dataset.
Weekly Status Update 9/29
Michael – I was working on researching different libraries for working with midi files. I have found http://www.midijs.net/midijs_api.html useful for playing back the midi files using javascript in the browser. I believe https://mido.readthedocs.io/en/latest/ will be useful for manipulating the midi data in python for our machine learning application. I am working on a web application to upload a midi file and play it back using midijs. I will continue to work on the web application and make sure our inputs and outputs match and are compatible with what we expect the inputs and outputs of our machine learning algorithm to be.
Chris – For the past week I have been putting most of my time and energy researching algorithms for chord generation, mainly BLSTM, and comparing them with RNN and HMM model. A few useful Python frameworks to look at might include Keras (https://keras.io/). We want to push to run some simple test on the music data we found last week with the LSTM model
Aayush – Studying the theory about neural networks and RNN’s to better understand how RNN’s are useful for modeling time series data. The aim is to design a simple test similar to the ones described in this paper: https://arxiv.org/pdf/1712.01011.pdf. We chose this paper as they had a well labelled dataset. Then we can develop a simple POC of our chord generation system and use the results to guide our design.
Weekly Status Update
This week we worked collectively on researching Machine Learning algorithms, devising strategies to acquire data, scheduling, and planning out certain design decisions of our project.
Aayush – I collected a dataset from Wikifonia.org, which is now a defunct website, but their data is still available in places online. I also researched on approaches to chord generation (https://arxiv.org/pdf/1712.01011.pdf). For the next week I plan to study more of the background described in music generation papers (HMM’s, Neural Networks).
Michael – I also researched chord progression and other related music generation papers using Machine Learning https://cs224d.stanford.edu/reports/allenh.pdf https://arxiv.org/pdf/1712.01011.pdf https://www.researchgate.net/publication/319524552_Deep_Learning_Techniques_for_Music_Generation_-_A_Survey
Chris- For the past week my main focus was to collect data, determine the usability of the dataset and to research on related fields. I researched existing tools to convert chord labels in music files into notes as many data we found has only the main melody well labeled while the chord progressions are labeled in plain text format. Useful tool: MuseScore, and useful plugin. For the first half of the next week, I will move onto researching algorithms for chord generation (BTSTM, Bidirectional Long Short Term Memory). For the later half of the week, I will work with my teammates to pre-process the music data if needed.
Our short term goal over the next few weeks is to run short tests (2-4 bars) that will help us scope out the task for the design review.