
Michael – The core functionality of our final webapp is working now. The user is able to upload a midi file without chords. The user is able to then generate chords and play the original and the melody with chords from the browser at the same time. The user can then download the file with chords at any time. Goals for this week include working with the midi keyboard and helping Chris incorporate what he has been doing into the application.Expanding the application to have multiple chord progressions once Aayush provides the multiple models will also be fairly trivial 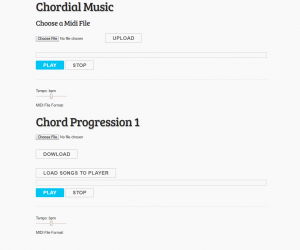
Chris – For the past week I have been working on the interface design for the web app, and I have got some pretty good results. After a few iterations of sketching and prototyping, I have landed on a visual structure and the corresponding color scheme. Improvements of the new design over the original design can be categorized into two aspects: the user experience and the visual. In terms of improvement on the user experience, I decided to break up the uploading interaction and the chord generation part into two interfaces because when user first land on our website, the interface should be a clear page with a description of what our web app does and a very clear call to action button (the Upload Melody button). The second improvement is dedicating the left part of the screen for clearer navigation. The content of the navigation menu is still to be decided as we add more/alter features of our product. In terms of visual, there are a number of changes, the most important of which are using blocks to create a more user-friendly visual hierarchy and displaying chord while the music is being played, which should be the central feature of our app. Other visual improvements include better color and typography choices to improve visual hierarchy, better organization of functional buttons, and more aesthetic rendering of the music. Finally, I also made a logo for our app. For the coming week, I will be working with Micheal to implement the design to the best degree. Some designs will be changed or dropped as always, and I will be continuing to improve the design as we go.
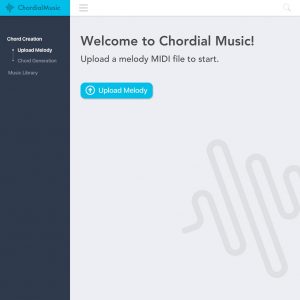
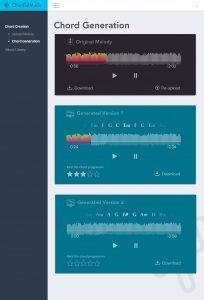
Aayush – I have been planning the final steps we need to take in order to prepare a test dataset for human evaluation. My initial goal was to use our chord prediction to ease the process of labelling the type of music we wanted (Beatle pop and rock). There were a few issues with Beatles songs that made this more difficult than anticipated:
- Beatles songs turned out to be far more complicated than I previously imagined, both in terms of chord changes and having more than one chord per bar.
- Songs often contain off-scale chords, which naturally makes prediction much tougher.
Nonetheless, we have managed to collect 20-25 single track Beatles melodies. I have processed 8 of these melodies (around 400 bars of music), 5 of which required major changes to our predicted output (> 60% of chords changed), while the other 3 required very minor changes (< 25% of chords changed) for a chord progression good enough to add to the training set. By changes I mean predicted chords I manually replaced.
Moreover, for non-simplistic melodies (usually characterized by a faster melody but not always), I noticed the output being extremely repetitive at random occasions, for example 4 C’s in a row where it should not have been. While training the data, I went for a less complicated model because test accuracy would not increase with model complexity. However, as I mentioned earlier, the predicted chords were much more varied with increasing model complexity. (For any complexity, the graph was almost identical except the number of epochs required to train)
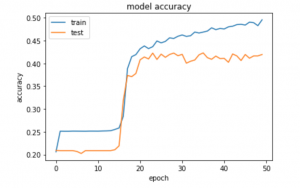
We were always aware that accuracy was a poor measure, yet defining another loss function seemed impractical given the lack of any good measure for test predictions. To tackle these issues, I think the following strategy would be most effective –
- Add modern pop songs to our dataset, which have much simpler chords. My aim is to have this as the vast majority of the dataset, so the network prefers simplistic output. The addition of songs form the wikifonia dataset and our collection of beatles songs can help add a small tendency for the network to take risks.
- Retune the network from scratch after accumulating the final dataset. It took me a long time, thorough testing, and detailed analysis of the output scores to finally realize the above issues with the network, implying the baseline model produced fairly pleasant sounds for the most part.
I will continue to test, fix predictions, and accumulate valuable training data for the rest of the week. With the evaluation looming I also chalked out a rough plan for the testing phase. For both the rating test and the confusion matrix –
- 5 curated songs where our network performs well. ( 2 of the Beatles songs could be used here, but I fell the retrained network can perform much better)
- 5 random songs chosen from our collection of pop songs.
- 5 composed melodies, not taken from original songs.
We will also collect data separately about which of the 3 groups performed best and worst.