What did you personally accomplish this week on the project?
- Thrashing with the NVIDIA Jetson
- This week, I spent a sizeable amount of time trying to get our server running on the NVIDIA Jetson. In our case, we ordered the Jetson to serve as something of a backup, in the case that our Raspberry Pi was not sufficiently fast to handle the desired incoming requests. As our bottleneck would likely have been running inference on YOLO, having a server with an integrated GPU would have helped this specific case.
- Until this point, I had only flashed the Jetson’s SD card and gotten it to boot, and hadn’t tried to install our server in any capacity. The main reason for this was because our Jetson did not come with wi-fi. At this point, I knew that Ethan had a wifi dongle from previous circumstances, so I acquired it and tried it out with the Jetson, to no avail. The dongle was windows-only, and downloading drivers would itself require having internet. Therefore, I needed some other way to get internet access.
- As my laptop has an ethernet port, I thought about using it as a proxy to connect the Jetson to the internet. However, it was not nearly as simple as plug-and-play, I then spend ~1.5 hours fiddling with various settings on both my laptop and the Jetson, and eventually managed to get the Jetson connected to the internet by running a few special commands, and adding some configurations to my laptop’s firewall.
- At this point, I tried to see if I could install drivers that would allow the Jetson to use the wifi dongle. I tried some directions provided by an amazon review of the same product, and instructions from various blog posts and forums, but nothing appeared to work.
- At this point I thought, “well if it turns out that the server runs really slowly, or not at all, all of this work would be for nothing”, and decided to try to get our server running. It was at this point that I realized that the Jetson was really old – the newest version of python it could run was 3.7. In spite of this, I managed to get the the server running on the Jetson’s CPU. This turned out to be incredibly slow, as I will show in a future graph. The model definitely wasn’t running on the GPU, and the only way the Jetson would be a good choice would be if I could get programs to run on the GPU.
- At this point I ran into a slew of problems trying to get GPU functionality to work. As the Jetson was old and ran Ubuntu 18, all of it’s packages were from the Ubuntu 18 era, meaning I had to try to find workarounds for many errors along the way. Additionally, I had some issues where I could not get the actual GPU drivers to install properly. I tried doing this by installing packages, downloading a new jetpack (which for some reason did not include the drivers), and trying to download the SDK manager (The source for the version I wanted literally did not exist for me to download).
- After several hours of debugging, I gave up on the Jetson. If anyone has any ideas of something basic I could be doing wrong, please let me know.
- Implemented performance metric framework
- Another large portion of my time was spent making a framework to make it easy to performance test our code.
- The functionality consists primarily of a python decorator. When this decorator is placed above a function, it makes it so that whenever that function is invoked, the function duration gets printed to a per-worker performance log file. Performance logging can be disabled by setting “PERF” to ‘False’ in our server configuration class (Config.py).
- Our framework uses the python logging package, which has a reduced performance overhead compared to manually sending output directly to file (This is good since slow logging means latencies appear worse than they actually are).
- Using the new logging functionality, and a basic trace, (which calls a few selected endpoints 10 times each), we were able to find how long each endpoint took to run compared to the others. Here is a graph of the information:
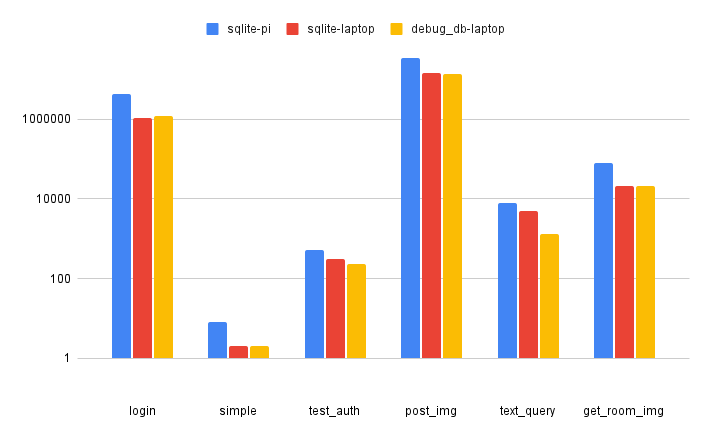
- For reference:
- The y axis is seconds * 10^7
- ‘login’ was only called once, and is not part of the test
- ‘simple’ simply returns status code 200 and does nothing else.
- ‘test_auth’ authenticates the user token, and immediately returns.
- ‘post_image’ recieves an image, and runs YOLO on it.
- ‘text_query’ recieves a text query (object) from the user, and returns a URL to the most recent occurrence of that object.
- ‘get_room_img’ takes in the hyperlink spat out from ‘text_query’, and returns the image file it references.
- I believe the most important takeaway from this graph is that YOLO inference vastly dominates the runtime of any other of the endpoints, taking >100x as long as even the next most expensive call, ‘get_room_img’. Our main server performance gains will come from decreasing the time spent doing YOLO.
- Another important takeaway is that the database used does not seem to have a large difference in the total runtime.
- We were also curious how long each of our devices took to execute YOLO, and took more measurements:
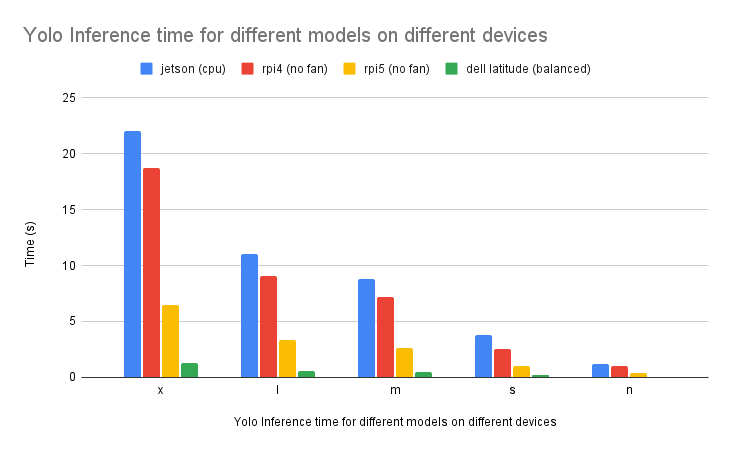
- Each of the letters on the x axis represent YOLO models of different sizes.
- From this graph, we can make a few observations:
- The Jetson, when used with its cpu, is unbearably slow. Unless we somehow magically get the CPU working, it is a lost cause.
- If we want to do inference on the pi4, we will have to considerably reduce the number of images we do YOLO on, either by sending images at a slower rate, or filtering sent images more aggressively.
- The pi5 nearly has enough speed to do inference on an incoming stream of 1 image/3 seconds. This may be feasible by doing basic optimizations on the model.
- Helping integrate database backend
- This week, Swati extended her database implementation with some new interface functions I added, and needed some assistance on how to integrate it with the webserver codebase without violating a bunch of interfaces.
- Restructuring and documentation
- As my groupmates are getting to the point where they need to be able to test their code on the webserver, I put some effort into facilitating this for them. I did this by:
- Documenting previously mysterious parts of the code, such as how performance monitoring is done, and the general layout of the server.
- Creating a small library of helper functions they could use to invoke the webserver endpoints without having to manually construct the requests themselves.
- Creating some useful scripts for common tasks such as
- Parsing performance logging output
- Sending a directory of images to the webserver (test inference speed, and get data into the server on which you can query)
- As my groupmates are getting to the point where they need to be able to test their code on the webserver, I put some effort into facilitating this for them. I did this by:
Is your progress on schedule or behind? If you are behind, what actions will be
taken to catch up to the project schedule?
My progress is on schedule for this week, though there are likely some other portions of the project on which progress must be accelerated, primarily the design of a good-looking website. I will discuss with my groupmates to ensure we stay on schedule.
What deliverables do you hope to complete in the next week?
I will have to discuss with my groupmates regarding which tasks take the highest priority for us. In our case, this could be any number of deliverables, such as:
- Improving the speed of model execution
- Try a different ML framework
- Create an inference server
- Adding authentication to the server
- Create optimizations to reduce the number of images to do inference on
- Creating optimizations to bound images stored in the database
- Creating “realistic traces” to test the previously mentioned optimizations
- Creating the new website
- Fixing database quirks
0 Comments