
This week – apart from the final presentations – I spent optimizing our pipeline so we can decrease latency (now we achieve about 25 frames per second on average), which is an important metric for our use case. Additionally, I am working with Neeraj to improve our model performance on a larger set of classes (we originally had 100 but now are pushing towards 2000). We realized a couple mistakes when training our previous model which affected the real-time performance (like training on frames which mediapipe did not recognize properly and having a static batch-size). Thus, we are changing the pre-processing of the data and retraining the model. I am on schedule for my deliverables and we hope to have a fully finished product by early next week. After I integrate the pipeline with Sandra’s LLM API code, I will work to implement the project on the Jetson.
Neeraj’s Status Report 4/27/24
Over this last week, I have mainly been focusing on changing the preprocessing of the model and retrain the model and avoid unnecessary details in our input images with Kavish. As of right now, we both have been tackling different fronts of the classification model and improving its overall metrics before we finish up integration by porting it onto the jetson. If anything else, I have also been messing with the idea of integrating a quick expression classifier that could aid with the LLM. Although a separate network, our current metrics show that we have the latency room to possibly add this in. It is also an idea that we have bene toying around with for a while as a group that could help in better translating ASL semantics, such as identifying if a sentence was a question or not. I intend on either finding a pretrained model or a quick dataset to train on so hat it is not a large investment, but it is also just an extra jump that we are considering making while our classification model is training and if we have the time.
As such, my main priority as of right now is to finish retraining the classification model, as that is one of the final things we need to finish up for demo day. If there is a lot of time remaining and there is nothing else for us to do, then we can look into the expression algorithm, but as of right now, I am not really considering it due to our time constrictions.
I would say I am around on schedule. I have finished integrating my part of the code with Kavish’s work, so he only thing left to do is retraining the model on my end. I also intend on helping out with further integration with the rest of the group as well. If anything, I am slightly behind due to the fact that I hoped to be done with the model by now, but testing and debugging during integration took longer than expected. Getting the model retrained and helping out the rest of the group with integration should help get us back on schedule.
Team Status Report 4/27/24
Coming into the final week, our project design consists of running MediaPipe’s HPE and classification model directly on the Jetson and connecting to OpenAI’s API for the LLM portion. A web server will be hosted locally through Node.js and display the video feed alongside any detected text. This week, we’ve focused on retraining our word classification algorithm and finalizing the integration of project components.
The main risk in the coming week before project demos would be unexpected failure of a subsystem before demo day. To combat this, we will document our system as soon as desired behavior is achieved so there is proof of success for final proof of concept. If retraining the word classification model lowers accuracy or creates failure due to the complexity of 2000 classification labels, we will demo using the smaller word classification models that have been trained earlier in the semester.
We are on track with our last schedule update and will spend the majority of the next week finishing project details.
When measuring project performance for final documentation, we used the following unit tests and overall system tests:
- Overall and Unit Latencies were calculated by running a timer around specific project components.
- The speed of our overall latency encouraged us to focus on accuracy and range of word classification rather than reducing latency. As such, we’re retraining our word classification model to identify 2000 words as opposed to our current 100.
- Recognition Rate was tested through measuring output/no output of the classification model in tandem with short video clips.
- Word Classification Accuracy was measured by running video clips of signs through the classification model and checking the output value against the video’s correct label.
- Inference Accuracy has been primarily gauged through human feedback when testing various LLM models’ need for reinforcement or fine tuning. A more complete dataset, predominantly informed by SigningSavvy, will soon be used to collect model-specific accuracy metrics.
Sandra’s Status Report 4/27/2024
This week, I worked on setting up an IDE environment on the Jetson Nano for Llama 2 and Node.js. Unfortunately, in the process I found the Jetson used an aarch64 (ARM) instead of a x86_64 (Intel) CPU architecture. As a result, the necessary local conda environment to enable Llama 2 wasn’t a feasible option. In the initial debugging phase, multiple developers who’d run into the same issue recommended I follow this article as a workaround for a conda-like environment (Archiconda). However, upon trial the Jetson experienced multiple dependency issues that didn’t have simple resolutions after attempting the first 3-4 viable suggestions (like running sudo apt update/upgrade or sudo apt-get autoremove to update/reinstall available libraries). Due to time constraints, I thought it best to follow the previously stated backup plan, working with OpenAI’s API. This would allow me to fine tune the GPT LLM simply without needing to rely on device/OS specific variability within environment and setup.
 here, you can see a few syntactically ASL sentences correctly translated to natural language English sentences.
here, you can see a few syntactically ASL sentences correctly translated to natural language English sentences.
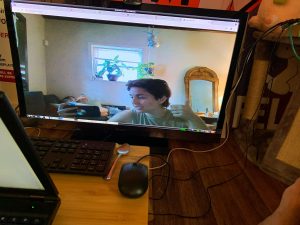 I was able to successfully install Node on the Jetson and create a simple local web server that displayed webcam input on a browser using the livecam library. As seen to the left, the monitor displays a live stream of the webcam connected to the Jetson. I have limited experience with front end development but will shortly be adding text and interactive features to the display.
I was able to successfully install Node on the Jetson and create a simple local web server that displayed webcam input on a browser using the livecam library. As seen to the left, the monitor displays a live stream of the webcam connected to the Jetson. I have limited experience with front end development but will shortly be adding text and interactive features to the display.
In the final stretch of our schedule, my progress is slightly behind where I’d like it to be due to the extensive time spent on debugging and testing multiple avenues for setting up an adequate LLM without needing to pay out of pocket.
By next week, the whole project will need to be fully integrated from end to end on the Jetson and stress tested. For me, that will mean setting up the proper connection with OpenAI on the Jetson and aiding in any integration issues or debugging.
Team’s Report for 4/20/24
Our project design has changed a lot throughout the last two weeks. Since the pose estimation model was not quantizable for the DPU, it could not be efficiently accelerated on the FPGA. Due to these reasons, even after improving the inference timings of the HPE model, it would make more sense data latency wise to actually run both the HPE and the classification model directly on the Jetson. This was one of our backup plans when we first decided on the project. There are not additional costs to this change. We are currently finishing the integration of the project and then measuring the performance of our final product. One risk is if the Llama LLM API use does not end up working then we will have to quickly switch to another LLM API such as GPT4. There is no updated schedule unless we cannot finish the final demo in the next couple of days.
Neeraj’s Status Report for 4/20/24
Over the past week, my main progress has been mainly retraining the classification model and integration of the model into the pipeline, namely with the HPE model. Since the last classification model was inaccurate, I decided to reprocess all of our WLASL training data and use that to retrain the model. I also did some small testing on a few hyperparameters, namely the learning rate and epoch counts. As such, I got a model with about 74%-75% validation accuracy. From there I focused on developing an inference script based on the spoter evaluation code, which we could use to input data into the model, receive a softmax output, and find the associated label with that. Since then, I have mainly been working with Kavish on integrating the HPE model and the classification model, determining the necessary data transformations we need to go through to translate the output of the HPE model into the input of the classification model. We also have been running latency tests for our components, looking at inference times and frame rates to make sure that we are staying within our design specification’s latencies.
As of right now, I feel like we are a little bit behind schedule, simply because we ran into a couple of unexpected issues during integration. But our main idea for combatting this is simply spending more time working it as a team to figure it out together in a more efficient fashion.
For the next week, my main focus is going to be any further testing and integration we might need alongside continuing final presentation work.
Throughout this project, I feel like one of the greatest sources of knowledge that I found was previous research papers. Especially when looking into video classification and how various models and architectures worked, reading through papers, understanding the purpose the research, and the detail within the papers themselves were a valuable medium. For example, reading between the MUSE-RNN paper, the spoter paper, the spoter-embeddings paper, and other papers that were related to WLASL were really useful to figure out how to tackle this problem in a real time setting. More specifically, they helped me learn about intricacies and relationships between nodes within neural network architectures, whether that be in RNNs or transformers. This even extends to online articles and videos discussing more base level topics that I could learn from to better understand these papers, such as Medium articles describing how various architectures worked was useful for understanding important concepts.
Kavish’s Status Report for 4/20/24
Over the last two weeks, I worked a lot on the FPGA development, which has led significant changes on our overall project. The first thing I realized after trying a lot was that the our pose estimation model (mediapipe) is not easily quantizeable and deployable to my FPGA’s DPU. I was able to deploy another pose estimation model which had all the supported operations and functions; however, since our classification model (SPOTER) requires mediapipe landmarks from both hands and pose, this was not a feasible option to pursue anymore. Thus, I began optimizing and finalizing the inference of the mediapipe model as much as I could and then began integrating it with Neeraj’s classification model. I designed the system structure and am currently trying to finish all of the integration. I hope to have the final pipeline working by tonight, so then we can do all of the testing and measurements tomorrow. We are a little behind schedule but hopefully by putting enough time over the next couple of days we can finish the final demo.
What I have learned: I have learned a lot of new tools with regards to FPGA development. In particular, how to use Vivado and Vitis to synthesize designs and deploy them on DPU’s. I also learned a lot of basics behind machine learning models like CNNS, alongside libraries like PyTorch. In order to do so, I relied heavily on online resources like youtube or research papers. Many a times I also followed along different articles written by individuals who have tried to develop small project on Kria boards.
Sandra’s Status Report 4/20/2024
This week I focused on fine tuning the Llama 2 LLM to modify it’s stylistic I/O so it better fits our needs. Words are classified one at a time and output with no memory so a separate program must be responsible for recalling past words and continually interpreting possible sentences. As such, I’ve modified the generation.py file to define the “system” role as an ASL language translator. The system is told “Your objective is to act as an ASL sign language interpreter. You will be given a sequence of words directly transcribed from signed ASL speech and correctly interpret the words in their given order to create full English sentences. You will receive a list of comma separated words as an input from the user and interpret them to your best approximation of a natural language English sentences in accordance with ASL grammar and syntax rules. Words that haven’t been given and exist in ASL should not appear in the sentence. Past word inputs should continue to be interpreted into a sentence with new inputs. Parts of speech like copulas, articles, adverbs, pluralization, and tense markers should be inserted into full English sentences when appropriate.” This behavior synopsis was developed earlier in the semester while gauging GPT’s ability to achieve our LLM needs without substantial model modification.
Additionally, behavior is further defined in generation.py using examples from a small dataset I collected while researching ASL grammar and syntax rules. Some examples include:
| last, year, me, went, Spain |
I went to Spain a year ago.
|
| house, I, quiet, enter |
I enter the house quietly.
|
| yesterday, I, go, date |
Yesterday I went on a date
|
| tomorrow, vacation, go, I |
I am going on vacation tomorrow.
|
I would also like to use HRLF (human reinforcement learning feedback) to refine correct/incorrect sentences and test for edge cases that may challenge common SVO sentence structure.
Over the next two weeks I’ll be integrating the final iteration of our LLM translation module with the classification model’s output and inputting text to our viewing application.
I am a bit behind schedule due to difficulties with Llama 2 environment setup needs on Windows. The Llama 2 Git repository is only officially supported on Linux and multiple debugging efforts have led to numerous issues that seem to be related to operating system configuration. It may be relevant to note: my computer has been sporadically entering BSOD and occasionally corrupting files despite factory reset so there may likely be device-specific issues I’m running into that may not have simple/timely solutions. As a result, I felt my time would be better spent looking for alternate implementations. I have tried setting up Llama directly on my Windows computer, on WSL, and through GCP (which ended up being essentially a cloud based host that required pairing and payment to VertexAI rather than OpenAI despite offering $300 free credits for new users). I am currently trying to set up Llama on the Jetson Nano. If issues persist, I will transition the knowledge I’ve gained through troubleshooting and working with Llama 2 onto the OpenAI API LLM.
In the next week I hope to have successfully set up and tested Llama 2 on the Jetson Nano and have finalized a Node.js local web server.
Neeraj’s Status Report for 4/6/2024
As of right now, we have a lot of individual components that are working, namely the HPE model and the classification transformer. We can take in a video stream and transform that into skeletal data, then take that skeletal data and process it for the model, and then run the model to train and predict words. However, each of these components is separate and needs to be joined together. As such, my current work is pretty set: I need to focus on developing code that can integrate these. While most processes can be explicitly done, some components, like model prediction, are buried within the depths of the spoter model, so while I can make predictions based on skeletal data after training, I need to pull out and formulate the prediction aspect into its code that can be used for live/real-time translation. Therefore, my main goal for the next week or so is to develop this integration code. Afterward, I intend to focus on optimization and improving the classification model further. This would involve retraining with new parameters, new architecture, or different dataset sizes, as that would allow us to better approach our benchmark for translation.
For the components that I have been working on, I have a few verification tests to make sure that the HPE to spoter pipeline works as intended. The first test is simply validation accuracy on the classification model, which I have already been running, to make sure that the overall accuracy we get for the validation set is high enough, as this would signify that our model is well enough generalized to be able to translate words to a usable accuracy. I would also be latency testing the inference time of the classification model to make sure that our inference time is within the necessary unit latency we set out in our design requirements. As for when the HPE and classification model are integrated, I plan to run another accuracy test on unseen data, whether that be from a video dataset or a created dataset of our own, to test generalized accuracy.
As of right now, I am mostly on schedule. I anticipate that integration will be difficult, but that is also a task that I will not be working on alone since the entire team should be working on integration together. As such, I hope that working with the team on this will speed up the progress. Further debugging and optimization should be something that I run in the background and analyze the results later to determine whether we should further optimize our model.
Kavish’s Status Report for 4/6/24
This week was our interim demo and I finish two subsystems for the demo: HPE on the FPGA and live viewer application for displaying the results. I have already discussed the live viewer application over the last couple of status reports. For the demo, I implemented a holistic mediapipe model for human pose estimation (full upper body tracking) on the programmable software (meaning the Kria SOMs). This model takes in a live video stream from a usb camera and outputs the detected vector points in json format through UDP over the ethernet. This implementation is obviously unoptimized and not accelerated on the fabric yet. Over the next two weeks I plan on accelerating this model on the fabric using the vitis and vivado tools and integrate it with the jetson. I am not behind schedule but depending on the difficulties I might have to put in more hours behind the project. By next week, I hope to have significant progress on putting the model on the dpu with maybe a few kinks to solve.
Verifying Subsystem (HPE on FPGA): Once I finish the implementation, there are two main ways I will be verifying my subsystem. The first is measuring the latency, this should be pretty simple benchmarking where I will run prerecording video streams and live video streams and measuring end to end delay till the model output. This will help me understand where to improve the speed of this subsystem. For the second part, I will be testing the accuracy of the model using PCK (percentage of correct keypoints). This means I will run a pre-recording and labeled video stream through the subsystem and ensure that the predicted and true keypoints are within certain threshold distances (50% of the head bone link).
Team’s Status Report for 4/6/24
After our demo this week, the two main risks we face are being able to accelerate the HPE on the FPGA with a low enough latency and ensuring that our classification model has a high enough accuracy. Our contingency plan for HPE remains the same, if the FPGA accelerations does not make it fast enough, we will switch to accelerating it on the GPU on our Jetson nano. As for our classification model, our contingency is retraining it on an altered dataset with better parameter tuning. Our subsystems and main idea have not changed yet. No updated schedule is necessary, the one submitted on slack channel for interim demo (seen below) is correct.
Validation We need to check for two main things when doing end to end testing: latency and accuracy. For latency, we plan to run pre-recording videos through the entire system and benchmark the time of each subsystem’s output alongside end-to-end latency. This will help us ensure that each part is within the latency limits listed in our design report and the entire project’s latency is within our set goals. For accuracy, we plan on running live stream of us signing words, phrases, and sentences and recording the given output. We will then compare our intended sentence with the output to calculate a BLUE score to ensure it is greater than or equal to 40%.

Kavish’s Status Report for 3/30/24
I have been working this week on finishing subsystems for the interim demo. I have mostly finalized the viewer and it should be good for the demo. Once Sandra gets the LLM part working, I will work with her to integrate the viewer for a better demo. I have finished booting the kria board and am currently working on integrating the camera to it. For the demo, I aim to show a processed image stream through the FPGA since we are still working on finalizing the HPE model. I have been having some trouble working through the kinks of the board and so I am a little behind schedule. I will have to alter the timeline if I am unable to integrate the camera stream by interim demo.
Sandra Serbu’s Status Report for 3/30/24
This week was focused on building an OpenAI API for text generation and integration with other project components. OpenAI’s text generation capabilities are extensive and offer a range of input modalities and model parameterization. In their tutorials and documentation, OpenAI “recommend[s] first attempting to get good results with prompt engineering, prompt chaining (breaking complex tasks into multiple prompts), and function calling.” To do so, I started by asking ChatGPT to “translate” ASL given syntactically ASL sentences. ChatGPT had a lot of success doing this correctly given isolates phrases without much context or prompting. I then went to describe my prompt as GPT will be used in the context of our project as follows:
I will give you sequential single word inputs. Your objective is to correctly interpret a sequence of signed ASL words in accordance with ASL grammar and syntax rules and construct an appropriate english sentence translation. You can expect Subject, Verb, Object word order and topic-comment sentence structure. Upon receiving a new word input, you should respond with your best approximation of a complete English sentence using the words you’ve been given so far. Can you do that?
It worked semi successfully but ChatGPT had substantial difficulty moving away from the “conversational” context it’s expected to function within.
So far, I’ve used ChatGPT-4 and some personal credits to work in the OpenAI API playground but would like to limit personal spending on LLM building and fine-tuning going forward. I would like to use credits towards gpt-3.5-turbo since fine-tuning for GPT-4 is in an experimental access program and for the scope of our project, I expect gpt-3.5-turbo to be a robust model for in terms of accurate translation results.
from openai import OpenAI client = OpenAI()behavior = "You are an assistant that receives word by word inputs and interprets them in accordance with ASL grammatical syntax. Once a complete sentence can be formed, that sentence should be sent to the user as a response. If more than 10 seconds have passed since the last word, you should send a response to the user with the current sentence." response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": behavior}, {"role": "user", "content": "last"}, {"role": "user", "content": "year"}, {"role": "user", "content": "me"}, {"role": "user", "content": "went"}, {"role": "user", "content": "Spain"}, {"role": "assistant", "content": "I went to Spain a year ago."}, {"role": "user", "content": "where"} ])
The system message helps set the behavior of the assistant.
eventually, we would like to use an Openai text generation model such that we provide word inputs as a stream and only receive text in complete English sentences.
SVO (Subject, Verb, Object) is the most common sentence word order in ASL and Object, Subject, Verb (OSV) necessarily uses non-manual features (facial expression) to introduce the object of a sentence as the topic. As a result, we will restrict the scope of our current LLM to successfully interpreting SVO sign order.
Neeraj’s Status Report for 3/30/24
My main progress over the past week has just been preparing for interim demos. As such, I have put a temporary pause on any significant innovation, mainly concerning modifying the architecture of either the HPE model or the spoter transformer. As such, I have been putting more time into getting the necessary data after HPE processing and training the spoter model on the data we want to train on. The only thing that I have been coding up is the eval function for the spoter model, which should hold public functions that can run inferences on a trained model. Since the spoter model was a model generated for architecture research, the main goal was to evaluate the accuracy and loss metrics of the model. As such, I needed to save the model post-training and utilize the given architecture to create our eval functions for inference. I am currently working on training the model, so I am planning to have the working model and eval function for interim demos if all goes well.
My main plan for next week is to continue to iron out the interim demo material until we present, and then after that, focus on debugging, retraining, and architectural changes to the model to improve performance. This mainly involves collecting validation data and modifying hyperparameters to maximize that and looking into further research to see what improvements I can make to the model that would not result in a large latency burden.
As of right now, I am just slightly behind schedule. If I can finish up what we need for the interim demo in time, then I should be relatively back on schedule, as I will have the time to test, debug, and configure our pipeline. In the case that I do not have my stuff finished in time, I would be behind. In this case, I would most likely ask for help from my teammates in order to help in debugging code that I need to or get help in migration and integration later on.
Team’s Status Report for 3/30/24
Our main risks echo those of our previous reports, namely models not working/accuracy, inability to use the FPGA for HPE, etc., which we have provided mitigation strategies for in previous reports. However, the main risk that we are considering right now, especially when considering the interim demo and our final product is integration between our components. As we are working to get our components up and running, we will soon begin integration, which could raise some issues in getting stuff working together. Our main mitigation strategy for this is focusing on integration early before improving the individual components. As such, we can have a working pipeline first before we focus on developing, debugging, and improving the individual components of our model further.
At this point, we have not made any large design changes to the system, as we have not found a need too. Similarly, we have not changed our schedule from the update we made last week.
Kavish’s Status Report for 3/23/24
I finished up the code for the viewer and synchronizer that I described last week (corrected few errors and made it product ready). The only part left for the viewer is determine the exact json and message format which I can change and test when we begin integration. I hoped to get back on the FPGA development and make more progress on that end like I mentioned last week, but I had to spend time on coming up with a solution for the end of sentence issue. The final solution that we decided on was to run a double query to the LLM while maintaining a log of previous words given by the classification model. The first query will aim to create as many sentences as possible based on the inputted log, while the second query will determine if the current log is a complete sentence. The output of the first query will be sent as a json message to my viewer which will continuously present the words. The log will be cleared based on the response of the second query. Although I am behind on the hardware tasks, Sandra has now taken over the task of testing and determining the correct prompts for the LLM to make the previous idea work, so I will now have time next week to get the FPGA working for the interim demo. My goal is to first have a basic HPE model working for the demo (even if it does not meet the specifications) and then spend the rest of the time finalizing it. I have updated the gantt chart accordingly.
Neeraj’s Status Report for 3/23/24
The main progress that I have made is looking into the spoter algorithm I found at the end of last week and understanding how it works and how to apply it. It utilizes pose estimation as input, so it fits in well with our current pipeline. However, we would most likely have to retrain the model based on our pose estimation inputs, which I plan to do later this week. There is also the question of integration as well, as I am not entirely sure how this model works for post-training for inference time, which I am also looking to figure out. I have also been looking into our human pose estimation algorithm as of right now. As mentioned in earlier posts, we were looking at adding a more holistic landmarking by including facial features in our HPE algorithm. As such, I have been looking into Mediapipe’s holistic landmarking model. While Mediapipe said that they are planning on updating their holistic model relatively soon, I decided to look at their older GitHub repo and determine what I can do from there. It looks like we should be able to implement it similarly to our hand pose estimation code. We can reduce the number of landmarks that our classification model works off of as well, as we don’t need any info on the lower half of the body.
As such, my plan for the next week is to focus on getting a rough pipeline from HPE to classification. There will be a need to debug, as there always is, but given that we have an HPE model and a classification model with spoter, I am going to be focusing on integrating the two so that they can be later assimilated into the other parts of the pipeline.
I am still slightly behind on my work, as bouncing between various models has resulted in a bit of a setback, even though finding spoter does put me relatively back on. There has been a slight change in work, as Sandra is working on the LLM side of things now after discussing with the team so that I can focus in more on the classification model. As such, getting a rough pipeline working should put me basically back on track with the slightly altered schedule, as I should have the time to debug and workshop the spoter architecture.
Team’s Status Report for 3/23/24
Overall, apart from the risks and mitigations discussed in the previous reports about the new spoter classification model and the FPGA integration, the new risk we found was the ability to determine the end of sentences. As of right now, our classification model simply outputs words or phrases based on the input video stream; however, it is unable to analyze the stream to determine end of sentence. In order to mitigate this problem, our current solution is to run a double query to the LLM while maintaining a log of previous responses to determine the end of sentence. If this idea does not work, we will introduce timeouts and ask the users to take a second of pause between sentences. No big design changes have been made until now since we are still building and modifying both the pose estimation and classification models. We are a bit behind schedule due to the various problems with the model and FPGA, and have thus updated the schedule below. We hope to have at a partially integrated product by next week before our interim demo. 
Team’s Report for 3/16/24
Apart from the risks and contingencies mentioned from our previous status reports, the latest risk is with out Muse-RNN model. The github model we found was developed in Matlab and we planned on translating and re-adopting that code to python for our use. However, the good part of the code is p-code (encrypted). Thus, we have two options: go forward with our current RNN and plans or try a new model we found called spoter. Assuming that there are problems with our current plan, our contingency is to explore this new model of spoter. The other risks of FPGA and LLM remain the same (since development is ongoing) and our contingencies also remain the same.
There have been no major updates to the design just yet and we are still mostly on schedule. Although we might change it next week because Neeraj might finish development of LLM first before we finalize our RNN.
Kavish’s Status Report for 3/16/24
This week I split my time working on the FPGA and developing a C++ project which will be useful for our testing and demo purposes. For the FPGA application, I currently in the process of booting PetaLinux 2022. Once that process is finished, I will connect our usb camera and try use my C++ project for a very basic demo. This demo is mainly to finalize the setup of FPGA (before I develop the HPE model) and test the communication bandwidth across all the ports. The C++ project is an application to receive two streams of data (a thread to receive images and another thread to receive json data) from an ethernet connection as UDP packets. The images and corresponding data must be pre-tagged with ID in the transmitting end so that I can match them on my receiving application. A third thread pops an image from the input buffer queue and matches its ID with corresponding json data (which is stored in a dictionary). It writes the data onto the image (could be words, bounding boxes, instance segmentation etc.) and saves the updated image to an output queue. A fourth thread then gets the data from the output queue and displays it. This project mainly relies on OpenCV for image processing and a github library (nlohmann) for json parsing in C++. I do not think I am behind schedule just yet and should be able to stick to the development cycle as planned. Over the next week I plan to finish booting the FPGA and then test running an image stream and across to the Jetson.