Leading into the Spring Break, my main goals were to continue work on our web application while continuing to develop ideas for implementation of the scale integration in our project.
Regarding the web application, we thought it would be appropriate to have a working demonstration of some of its basic features ready by our next weekly meeting with TAs and instructors – planned for Monday, March 11th. Because hosting it on the Amazon Elastic Compute (EC) instance is not a must for this meeting, we will perform this demonstration on a localhost and will focus on site navigation, frontend development, user-user interaction, and view routing in the presentation of our progress to the course staff. This has been a shared effort amongst the entire group; I would now like to share some of my contributions to the web application:
Google Oauth Feature that registers and authenticates users with their Gmail addresses:

Weight-tracking visuals implemented with chart.js (a JavaScript framework for data management and plotting):

This, along with general routing of the pages, constituted some of the things I worked on the past 2 weeks on the web application front. We hope to flush out some of the main features under the context of user-user interaction, such as posting progress, friend networks, following/unfollowing, and chatting with Websockets, in time for the demonstration on Monday.
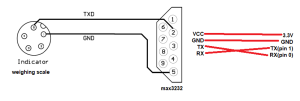
With the scale integration component of the project arriving soon, I took some time to compare and contrast the numerous market options. I had been hesitant to start ordering parts due to my unfamiliarity with the market options; however, in preparation for the design report, I performed a thorough evaluation of the possible microcontrollers that we could use for this stage of the project:

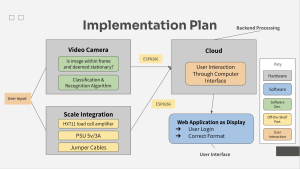
The market evaluation and design trade studies sections of the report required a thorough evaluation of factors I hadn’t previously considered, such as power consumption, pin layouts, and opportunities to streamline the entire design pipeline through custom SoC options. Favoring simplicity for the MVP, we will proceed with ESP-related options for scale communication, while researching more robust and impressive options in parallel. The benefit of these SoC designs is the potential to integrate camera and scale communication all in a single chip. This would greatly reduce the complexity of the project and alleviate concerns with separate stages of the project working with one another. Still, we consider this a potential stretch goal in the context of a simple yet effective MVP.