Accomplishments
For this week, I found a few datasets to train my model on
The first one can be found here: https://universe.roboflow.com/furkan-bakkal/shopping-cart-1r48s
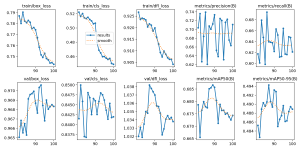
I used YOLOv8 to train a model and the results were quite good at first glance, with the best model having roughly 90% accuracy.

However, after looking through some of the validation data, it doesn’t look promising. Here’s one of the validation batches:

The image is pretty blurry, but the important thing to note is that the model performs poorly with realistic backgrounds (as opposed to plain white). I think it’s inaccurate enough to where tuning the hyperparameters probably won’t increase the accuracy significantly enough.
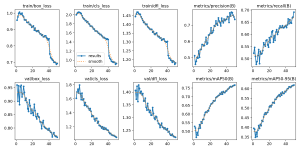
I used another dataset to train a model after deciding that the first one probably wouldn’t be good enough. Link here: https://universe.roboflow.com/roboflow-demo-projects/retail-nxvjw
The results are similar at first glance:
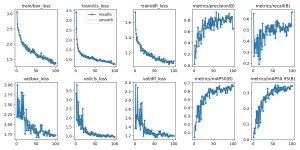
Looking through the validation batches, however, it seems to perform much better than the first model. Because the dataset includes much fewer images with white backgrounds, the new model looks to be significantly better than the old one at detecting shopping carts despite noisy backgrounds. I think I’ll try to tune some of the hyperparameters (such as number of epochs trained and image size) to see if the accuracy can be improved further.
I found one more much larger dataset that I’m currently training, but it isn’t done yet at the time of this status report, so I’ll check the model in a few hours.
Lastly, I learned how to use OpenCV to apply Gaussian blur, perform edge detection, and find contours, which is hopefully a good starting point for detecting how full shopping carts are, since we plan on NOT using a CV model for this part of the system. This is what an example currently looks like:

As it stands right now, this could be much improved. I will be looking into how I can use OpenCV to perform image alignment this upcoming week.
Progress
I think I’m still quite behind where I need to be at this point. For next week, I hope to refine the model I currently have a little further by tuning some hyperparameters and training again. Then, I need to see how it performs by actually feeding it camera footage of shopping carts from one of our cameras at the angle that we plan on using. As for the object tracking of the carts that I mentioned last status report, I no longer think it will be necessary, since we should only need to know how many carts are in a line at a given time, but I will check with my teammates to confirm. Lastly, I hope to figure out how to correctly implement image alignment so that the shopping carts will be consistently aligned to increase accuracy when we estimate the fullness of the carts.