Progress
I realized that when reading the time signature form options what is being processed is the number as a decimal in python. Therefore, I had to make a switch statement and give the time signature of 6/8 a different value when selected than that of 3/4 since otherwise, they would have the same value.
I also implemented a function in the backend that calculates the number of staves that we will need to draw dependent on the duration of the audio file.
I developed the front-end code for the save pdf button that we added, and I helped Kumar with ideas of the implementation of the backend function that turns the Vexflow output to a PDF when the user clicks on the “save-pdf” button.
Like we discussed in the Team Status report we are having issues with some audio files. Therefore, I tried to record the output of Twinkle Little Star with my phone and send that audio file to our system to process. It seems like some audio files are able to be handled but others give us errors. We are still not sure why this is occurring and therefore part of the focus of next week will be to figure out why.
I also cleaned up code accross project by removing dead code and adding documentation to make sure we are all on the same page and have an easier time when trying to understand each other’s code.
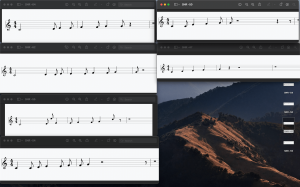
I finally edited the code that we had that drew the notes using Vexflow. Before, we looped all the time through the notes and when we reached the notes that had assigned a specific stave, drew them into that stave. This is inefficient because we loop through all the notes all the time, even though we only need the notes belonging to the stave we are drawing at that iteration of the loop. Therefore, I modified the way the notes were being processed and made a dictionary that matched staveIndex to the notes. Now, we just access the notes by getting the value assigned to a stave index and have reduced the complexity. The system did indeed get faster.
We should be on track in terms of progress.
For next week, I will be focusing on trying to figure out the issues with the audios, as well as helping my teammates out in whatever they need from the current tasks they are doing, since I know at least Kumar was facing issues implementing the backend of the save PDF button.
Testing
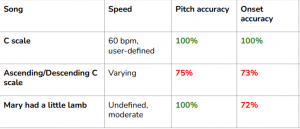
We will need to test the output of our integrator system. We have already started testing it by recording simple audios with the piano and feeding it into it. We will first need to test that the amount of notes in a stave is correct. We can test this by looking at the time signature and ensuring that the total length of the notes in a stave is less than the time signature, and that the note going into the next stave could not be added to the previous. We will also need to test that the amount of notes is correct. We can do this by listening to the audio and counting the amount of notes that we have heard and then count the number of untied notes that our integrator outputs. We should also test the accuracy of the pitches of the notes. We can do this by recording the notes pitch and comparing the notes pitch that our integrator outputs. Since we said we wanted it to be >= 90% pitch accuracy accurate, as long as it meets this threshold we should be good. We should also test smaller functions, like the function I created to compute the number of staves. This can be done by looking at an audio file and calculating how many staves we need for it and then comparing it to the output of our function.