Team Status Report for 03/18
What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
As of now, the current biggest risk is still the pitch tracking algorithm, especially since we just pivoted it to read in a .wav file rather than a continuous stream of audio input. With our pitch tracking algorithm, our biggest concerns are latency and accuracy.
Let’s talk about latency. As of now, Kelly’s .wav input pitch tracking algorithm is processing a 13 second audio in 0.029582977294921875 seconds ~ 300 milliseconds from start to end. While this may be higher than our latency cap, this chunk of 13 seconds is a much longer .wav input than we expect to be sending to the backend at once. Therefore, we are not currently concerned about meeting our latency goal, but further testing will need to be done once integrated with our web application frontend. In general, if we find that the latency here is too long, we have a couple of options: limit the duration of the .wav file we send to the backed and/or limit the amount of processing we are doing on the .wav signal.
Now let’s talk about accuracy. Kelly tested the new pitch tracking algorithm on 6 .wav files split between 2 files: C Major Scale – Slow and C Major Scale – Fast. The 3 .wav files for each scale version (fast and slow) were the following: straight piano input, humming input, note names input (i.e. Do Re Mi Fa Sol …). The results of these tests can be found in the following graphs:
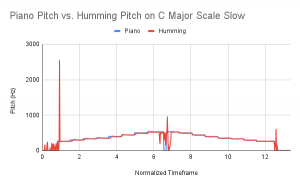

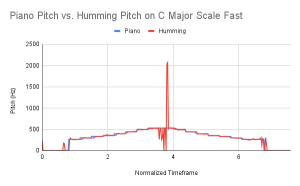
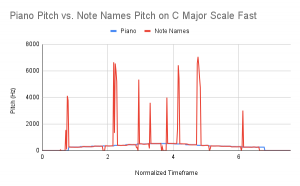
Overall, the pitch tracking is looking extremely accurate when comparing the piano input to a singers’ input. Obviously, there will need to be some filtering done on this signal, especially when using words as the air expended when consonants are used tends to throw off the pitch tracker. However, this testing leaves us pretty satisfied with the current setup. If further accuracy is needed, we will consider processing the signal more than this by using some sort of bandpass filter in order to eliminate the interference of noise.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
The addition of MediaStream and the subtraction of PyAudio were made this week. MediaStream is going to provide a continuous recording stream of the users voice on the web application frontend in javascript. This was previously being handled by PyAudio, but we couldn’t figure out how to properly communicate a python PyAudio stream to the javascript frontend. MediaStream will now send a .wav file to the Aubio backend which will then send back the pitch found.
This change was necessary in order to get pitch tracking to display on our web application. However, this change comes at the cost of about a week of progress. As we left 5 weeks of slack for pitch tracking, we just tapped into one of those and didn’t affect the progress of our project too much overall.
This is also the place to put some photos of your progress or to brag about a component you got working.
This week was very coding heavy, but we’re quite proud of the new pitch tracking algorithm and our lovely new graphs of testing.