If you’ve already looked at our individual reports, you’d know that much of our week was spent on realizing the Y2k22 issue with Vitis, so we won’t go on too much about it here. Instead, we’ll focus on the positives. 😊
To start, we now have a local instance of Vitis running on Alice’s laptop! The point of this is that we will no longer be restricted to the build tools present on the ECE machines. As the current Scotty3D code runs on a newer version of CMake, the ECE machine was unable to compile the program. Things should be more straightforward on a local machine, where we can easily install whatever packages we need. In any case, it seems like our build platform woes are hopefully coming to an end…
In terms of algorithmic improvements, we met a couple times throughout the week to analyze the code in the fluid.cpp file itself, rather than just identifying the dependencies in the overall algorithm. Of primary importance for these meetings was determining how to represent each of the datatypes and determining what data we would be able to store on chip in the BRAMs, as well as how many copies of the data we would actually be able to store. One particular structure of importance was trying to figure out how we would actually implement the neighbor map on the FPGA. In the regular implementation, the neighbor map is simply an unordered hash map that uses a nearest quantized point to index into a list of neighboring particles. While this implementation is fine in software, if we actually want a performant hardware implementation, we’ll likely need to manually implement the hashmap as a BRAM array of pointers to another BRAM array of particles. Aside from that, we also took a look at the looping structures in the code and assessed its ability to benefit from pipelining. In fact, we found that a lot of the steps in the code could actually be pipelined. Steps 2 and 3 seem to have no interdependencies, so we can probably unroll and pipeline those two steps. Other than that, we also took note of the instances of multithreading code that we would need to strip from the fluids.cpp file due to depreciation.
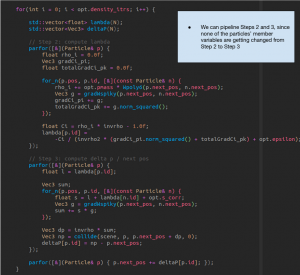
For the next week, our primary goal is to get a build of the fluids.cpp kernel working in Vitis HLS, as this will give us the baseline results we need.