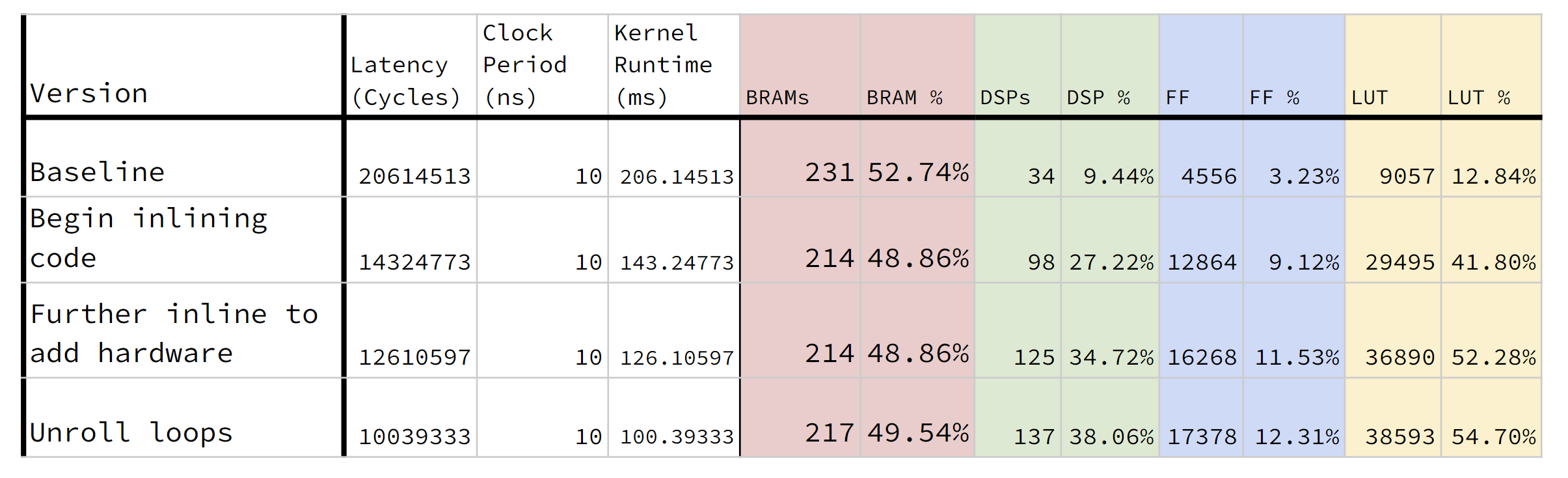
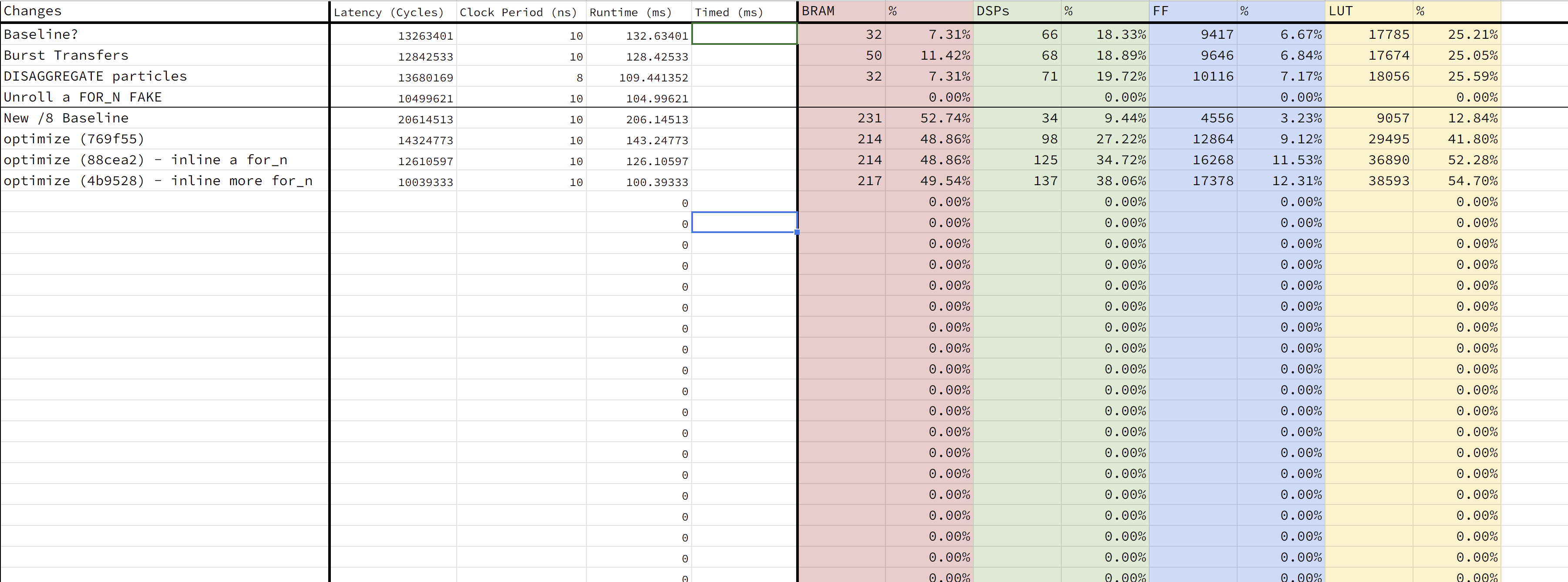
This was another good week for progressing in hardware-land. The first major contribution of the week expanding the AXI port so that we could transfer a whole Vec3 per transfer, rather than just a single position primitive (our 24 bit particle_pos_t datatype). The simpel effect of this optimization is that if we can move more data per transaction, this means we need fewer transactions to move all the data and thus spend much less time. In the simple example of grouping the three primitives together, this means that we’ll have three times fewer transactions overall, which roughly corresponds to a three times speedup. If we wanted to further send multiple Vec3s per transaction, we could save even more time; however, this could also lead to us hitting the upper bound of a 4kB page per burst transfer.
In order to implement the port widening, we needed to create an arbitrarily-sized datatype that is 3 times the width of a single primitive. Then, we would cast our writes to the output port to the 3-wide packed datatype. This seemed to make vitis happy enough to pack the data together.
Related to port widening, the next major contribution was implementing pipelined burst AXI4 transfers. Basically, the point of having a pipelined AXI transfer is that you amortize away the setup costs of having an isolated transfer and you gain significant throughput boosts from having a pipelined transfer.
However, it should be noted that in order to widen the ports, we needed to preprocess the particles position array by transfering every data value into a contiguous BRAM. This constitutes a pretty obvious design tradeoff for our project, where we expend more resources (and time!) in the effort of saving even more time overall.
As for next week, my next task is to accelerate the step5 loop and finish verifying the data transfer interface.