With most of the baseline operations implemented and verified, most of the time for this last week was spent on finalizing integration and adding some extra touches to algorithm and the different scenes we want to demo.
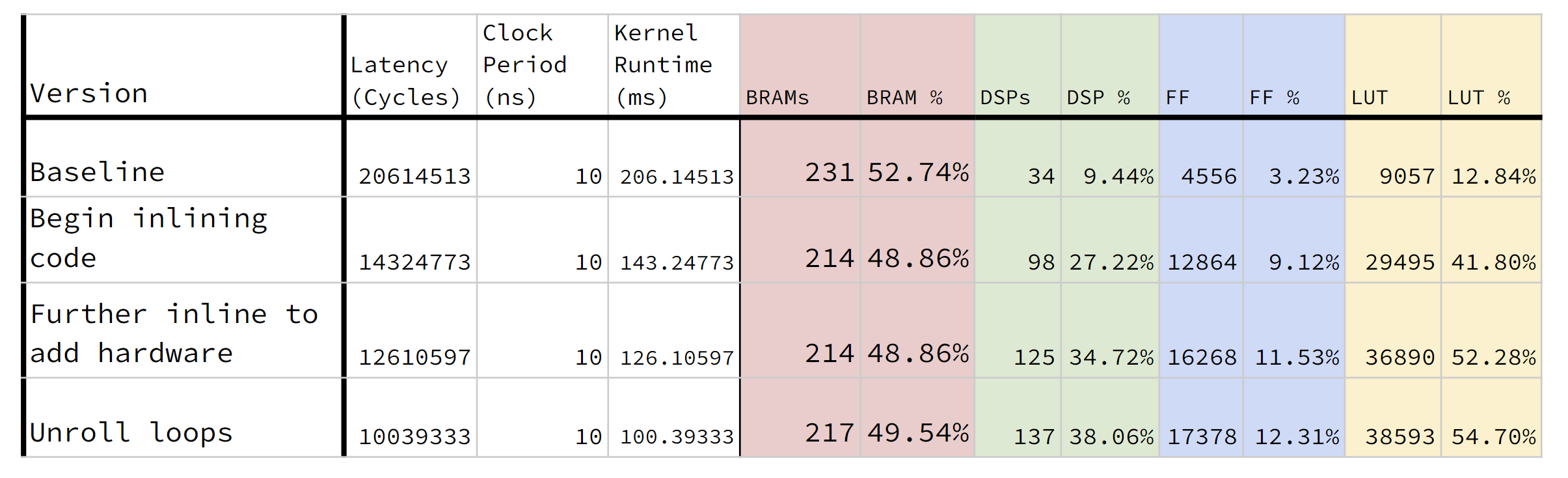
On the hardware side, we finalized how we would handle the interfacing between the Host CPU on the FPGA and the FPGA fabric itself. After some testing, we realized that the our port-widening scheme resulted in some faulty values being translated. We believe that this was due to how our datatype is only 24 bits, while the ports would have to be multiples of 32 bits wide. We think that this offset might be messing up our pointer-casting data-packing scheme. However, this is not really that big of an issue, as we can just have a longer burst transaction length. Furthermore, testing the different kernels on the FPGA yielded similar timings as well. It seems that as long as the transaction was bursted, the specifics did not really matter. (Amdahl’s Law suggests that we should turn our attentions elsewhere :^) ). Other than that, we decided to unroll a couple more things, and we mostly locked in our final code.
On the software side, we focused on adding support for displaying new scenes. There was some exploration into supporting other types of primitives such as quads and even meshes, but with a week or two left it was decided that we would just add support for more spheres (the alternative would be looking into compiling OpenGL on the Ultra96 and/or a major refactor for supporting a general Shapes class and changing a lot of std::move operations). We also figured out a new way of visualization so that we could compare the fluid simulation traces directly as point clouds. We still need to do some timing for data transfer between the Ultra96 and the host computer, but that should be trivial since it’s just an scp operation and then using a built-in timing tool in terminal.
Overall we’re pretty excited that our project actually works and we have cool things to show off now. We just need to get a lot of specific timing numbers down to address our requirements now, but we’re confident that we can get that done in the next couple days in time for the presentations.