This week was a bit confusing in terms of workflow for me. As of now, we are still trying to fully compile the project on Vitis. We had to deal with some troubleshooting in terms of connectivity to the FPGA, but I would say that the build system is mostly stable (Nothing that can’t be solved by the solutions we had from last week).
Other than this, most of my effort this week was spent on trying to figure out the best way to implement the nearest neighbor lookup for the fluid simulation algorithm. We realized that this issue was of primary concern, as how we would choose to store these values would determine the distribution of BRAM usage between the pipeline stages, which would in turn determine the overall organization of pipelining and unrolling for our kernel. First of all, at the beginning of the week, we thought we would be using a three-level hashmap to implement the lookup from (X,Y,Z) address to the neighbor list.
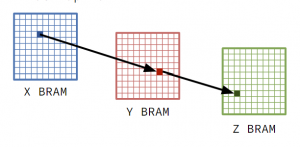
The problem with this design is that while it would theoretically be great for a sparse tree (which is what our hashmap would likely represent), the implementation is actually not realistically realizable in hardware. Since you can’t “allocate” a BRAM in realtime, every pointer in each of the BRAMs must have hardware backing, so every pointer must point to a dedicated BRAM. A back of the envelope calculation tells us that if we used integers to index, we would need 2^64 BRAMs to implement this design. Note: This would require 8.5 *(10**16) Ultra96s to implement..
Instead, we realized that we would need to implement some restrictions in order to feasibly implement the kernel. Our first idea was to figure out the realistic range of both the (X,Y,Z) points and the number of neighbors within a hash bucket. For the first part, we figured that this was important in that we could choose to restrict the simulated fluids into a “simulation window,” where every point that falls out of this window is removed from the simulator task. This also has the effect of reducing the address space we need to support for (X,Y,Z). If this value is small enough, then we could create a unique hash that can fit within 32 bits just by bit-shifting the (X, Y, Z). For the second part, we want to figure out a resonable upper limit for neighbors so that we can determine how wide the BRAM needs to be in order to store a list of all the neighbor pointers. As a side note, we note that with a simulation size of 512 particles, we can uniquely address each of the particles using a 9 bit address. We will need to investigate how we can efficiently pack this as a struct in the neighbor array in a way that works with the C++ for Vitis HLS.
As for next week, we will continue rewriting the C++ to allow for Vitis HLS compilation of the fluid simulation kernel.
