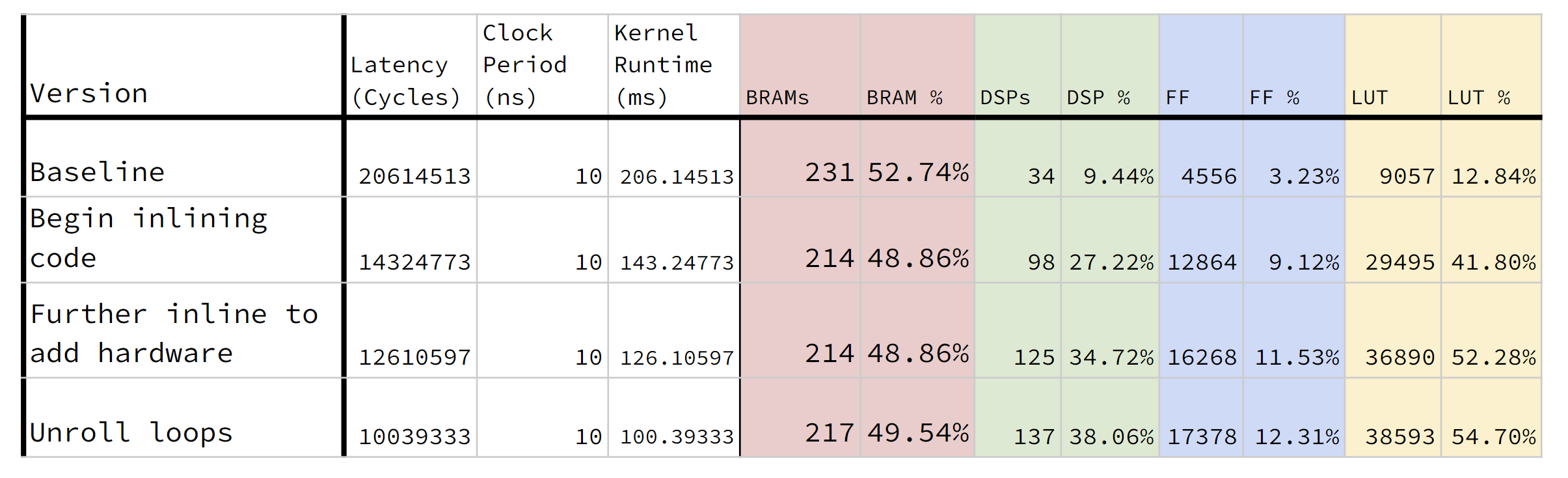
Turns out the numbers that I had gotten for Chamfer distance were off and they were even closer than I expected to the reference :). I got support for multiple spheres working and I was able to come up with a new visualization to confirm the fluid simulation traces matched as well.
My goal for this upcoming week is to re-generate all of the reference fluid simulations, record those and get log files, and then get log files from the FPGA fluid simulations and get Chamfer distance numbers. I also want to use the new visualization method to compare the fluid simulations as point clouds for easier visual verification. This will also provide as a nice graphic for all of our presentation materials.
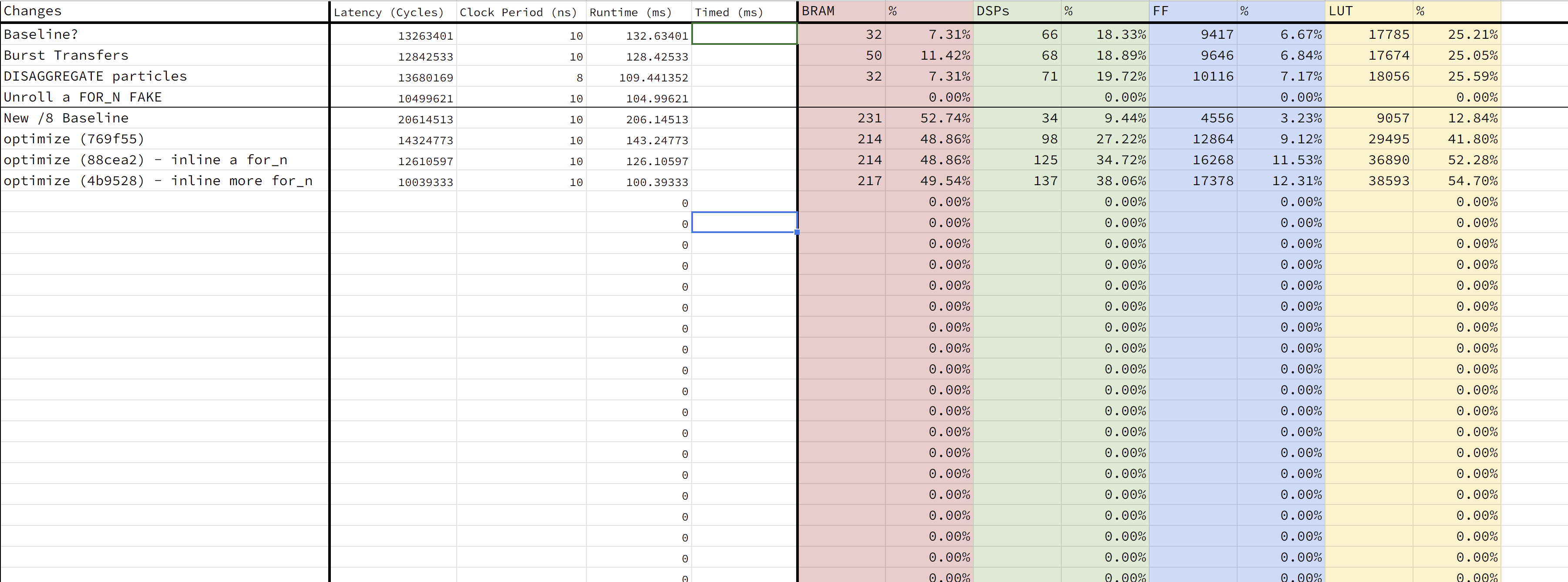
We’ve more or less locked down our final code version, just need to verify everything and document all of our hardware improvements with timing numbers. Feeling great that our project finally has something visual for results 🙂