This week I focused on researching for and deploying pretrained ASR models to verify that the current deployment strategy works. After successfully deploying a pretrained English ASR model and a pretrained Mandarin model, I noticed a critical issue that is slowing down our app performance when testing them, which I am still trying to resolve.
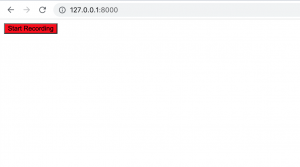
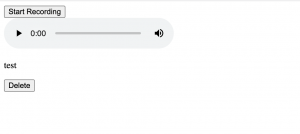
The ASR models I tested were from huggingface repositories “facebook/wav2vec2-base-960h” (an English ASR model) and “jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn” (a Mandarin ASR model). The deployment server was able to run our application, load an ASR model, take audio data sent from the frontend through HTTP requests, write audio data into .wav format and input .wav file into the model and send back predicted texts to the frontend. As demonstrated in screenshots below. Since this is only a pretrained basic ASR model with no additional training, the transcription accuracy is not very high, but it verifies that our current deployment strategy is feasible for deploying our own model.
![]()
Similarly, I successfully deployed a Mandarin ASR model.
![]()
On the way, I encountered 2 issues, one of which has been resolved and another still requires further researching. The first issue was that the running django server would automatically stop itself after a few sessions of start/stop recording. Through research, I found that the issue was caused by a type of automatic request made by a django module, so I customized a django middleware that checks and deletes such requests.
The second issue was that as the frontend was recording audio chunks to the server, the audio chunks starting from the second chunk will result in empty .wav files being formed. I am still researching the cause and solution for this issue. But for now, I changed the frontend logic to send the entire audio track from the beginning of a start/stop session to the current time to the server instead of sending chunks, which removed the issue. The drawback of this workaround is that the model needs to run on the entire audio data from the beginning of a record session instead of only running on a chunk every time. Plus, as we decrease the audio sending period, the model would have to run on more and more audio data. For example, if the audio sending period is 1 second, that would mean that the model would have to run on a 1s audio from the beginning of a session, a 2s audio from the beginning of a session, … , a n-second audio of the session. The total length of audio through the model for a n-second recording session is O(n2) whereas if we could manage to correctly send n 1-second audios, the total length of audio through the model for a n-second recording session is only O(n).
Next week, I will work on fixing the empty audio file issue and deploy a pretrained language detection model on our server so that the language detection model could decide for each audio frame which language model should be used to transcribe the audio to achieve codeswitching.
Currently on the web application side, there has not been any major timeline delay. I expect the empty audio file issue to be resolved within next week. Potential risks include that our own models might have environment requirements or performance requirements that are different from the models I have tested so far, so in that case the development effort for deployment and integration would be larger.