
On the webapp development end, we created two new features that could increase the transcription accuracy while preserving a relatively good user experience. We compared both features for their speed and accuracy, and two features each wins in one aspect.
The first feature is to resend the entire audio to the model for re-evaluation after the user stops recording an audio. Then we present the re-evaluation transcription to the user at the bottom of the original transcription and allow the user to choose whether to use or ignore the new transcription and thereby achieving a whole-transcription-level autocorrection suggestion.

The second feature is to resend the last 3-second audio to be re-evaluated by the model every 3 seconds as the recording is still happening. Then when the re-evaluation output comes back for the 3-second audio, we replace the original transcription for that piece of audio and thereby achieving a similar autocorrecting effect of Siri.
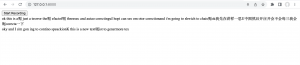
We see that the transcription accuracy of the entire audio from the first feature is significantly better than before and than the 3-second-chunk “autocorrection” from the second feature; however, if one audio recording is very long, the “autocorrection” from the first feature could take a long time (approximately as long as the audio itself) to be returned by our model. In comparison, the second feature does slightly improve the transcription accuracy but experiences almost no sacrifice in throughput. With the re-transcription and autocorrection every 3 seconds, the user experience still remains smooth and close to real-time.
Our next step is to further improve our transcription accuracy by incorporating Nick’s newly trained ASR model (trained on a larger dataset which should have higher transcription accuracy) and evaluating our model using more diverse audio samples collected by Marco’s audio collection site. Our project in terms of integration and evaluation are on schedule so far.


