
This week training began successfully on the LID model using the data we intended. It was able to complete its first epoch in about ~12hrs with promising initial prediction abilities. Next steps will be integrating the model along with Marco’s ASR module. The current model size is about 1GB uncompressed so I do anticipate meeting our size requirements to be begin to be a challenge. Exploring ways to quantize or otherwise compress the model may be investigated over the next week as will testing and training no noisy data using things like SpecAugment. Actual inference times seem to be around a second which is a promising result with respect to meeting our timing targets.
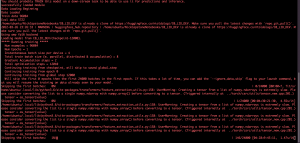
On the webapp side, we were able to achieve analyzing audios by chunks to greatly improve the system run speed. On the user level, we were able to create a real-time experience for voice-to-text. We also tested our system speed on larger ASR models and still got near real-time transcription.
Next week, we are expecting to have a trained language detection model, which we can start integrating into our deployed web app. So far, the development progress is on schedule. Potential risks include that the training of two languages’ CTC models may take longer than expected to get workable results, which could delay our integration timeline.