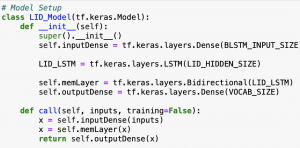
This week I was heavily focused finalizing and documenting the specifics of our system’s language identification model as well as other part of our systems overall language model design. I was able to upload the SEAME dataset to my storage instance on AWS and have begun working on setting up my training schema (data loading, validation and evaluation set partitioning etc..). In this I do find myself a day or two behind our schedule. I plan on spending all of Sunday working exclusively on getting the system entirely orchestrated so that all I have left is to make model architecture or hyper-parameter adjustments. I’ll be ramping up this week starting with a very small model and ramping it up as I validate each successive round of results. Given that we have a break coming up, it is crucial that the full system be able to train overnight by the end of the next school week. This will be my primary focus in terms of implementation.
Otherwise, most of my time this week was spent on our design document and sub-module specifications including unit tests, metrics and validation. Though our final design document still needs work in terms of formatting, I did a lot of our specification and explanation in a separate shared document which will allow for easy transfer into the document for the coming deadline.