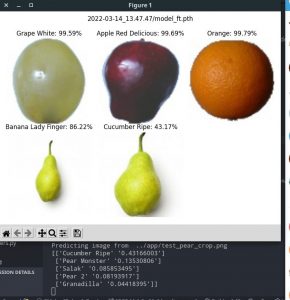
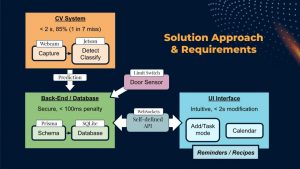
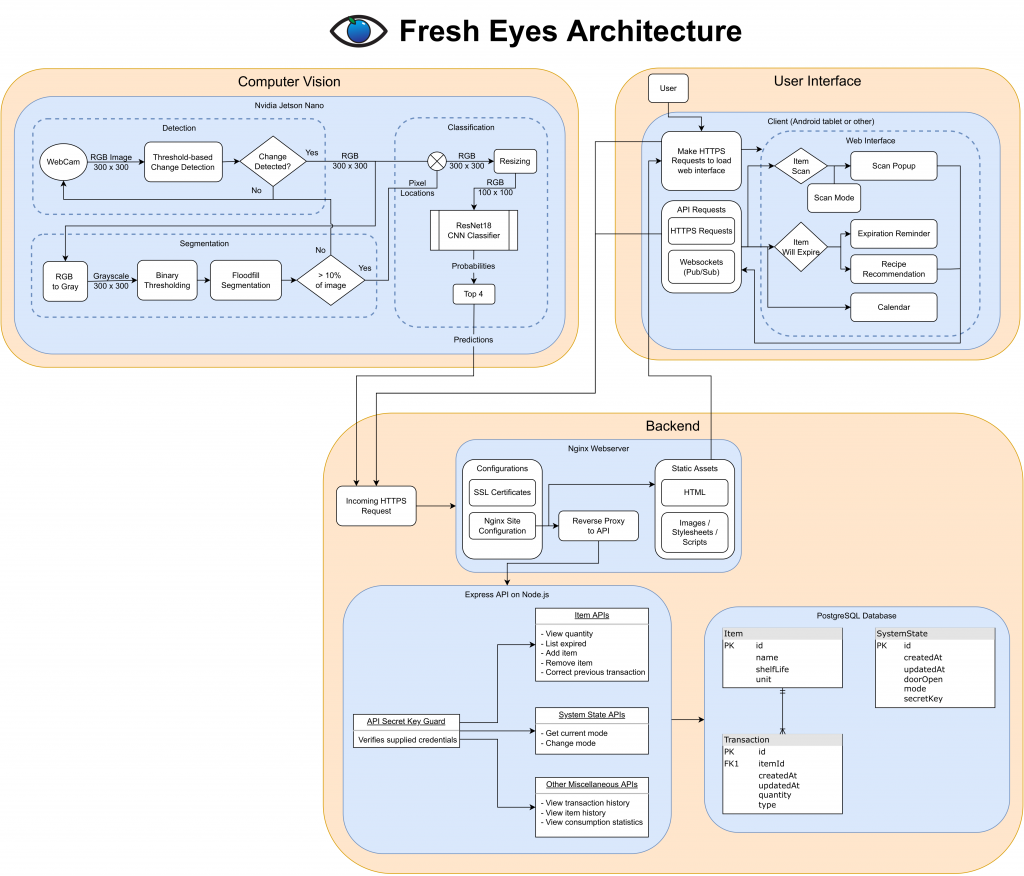
Indeed, as I’ve talked about in the team status report, we are now entering the phase of the project where the fun truly starts, and the product begins to take shape. This week, I kicked off the integration process between the front-end and back-end, ironing out kinks such as CORS header mismatches and API design issues, paving the road for full integration ahead. Right now, the front-end is now able to display real expiration dates fetched from the API. The back-end API had quite a bit of work done to it as well. Logic has been added for when items are replaced into the fridge, ensuring that the item count and expiry dates remain correct even when the same item is removed and placed back into the fridge. This is done by storing the state of the fridge – new items are only added to the tally when it is in “add” mode, i.e. when the user is loading new groceries from the store. All other additions in the “track” mode are considered replacements of previous removals.
The back-end API had quite a bit of work done to it as well. Logic has been added for when items are replaced into the fridge, ensuring that the item count and expiry dates remain correct even when the same item is removed and placed back into the fridge. This is done by storing the state of the fridge – new items are only added to the tally when it is in “add” mode, i.e. when the user is loading new groceries from the store. All other additions in the “track” mode are considered replacements of previous removals.
We’re still healthy in terms of schedule, but with just a bit over a month left, time can get a little tight if we are not careful. Going forward, we will be integrating the back-end with the Jetson and CV system, and I will also continue working with Alex to bring other aspects of the front-end into fruition, such as editing previous transactions.