
Final Video: https://youtu.be/hp0plAxwQCk
Final Poster
FreshEyes – Final Poster (High-Res PDF)
See also page for final product: http://course.ece.cmu.edu/~ece500/projects/s22-teamb3/final-product/
Low-Res Image:

Oliver’s Status Report – 30 Apr 2022
This is the last status report for the project! As we step in finals week, I crafted and presented the final presentation, and the final presentation seems to have turned out well!
The CV system is now also capable of making quantity guesses. I updated the API specification on the backend to support the new capability in order to allow quantity information to be sent from the CV system to the backend, and then to the frontend for display in the confirmation dialog. This required a mini-rewrite of the schema as well as the relevant API endpoints, but it was not too troublesome and I was able to deliver it in just 2 days.
In preparation for the final presentation as well as poster, I updated the overall architecture diagram, and consolidated test results and compared them against our use case requirements. All our explicitly defined use case requirements have been achieved! (see presentation) This is a testament to our good work both individually and as a team.
Coming up, there are some stretch goals and “nice-to-haves” that we can try to implement. Of higher priority is the final report and demo, and with that we will wrap up our project, on time and on schedule!
30 Apr 22 – Team Status Report
Most of this week was spent preparing for the final presentation, demo and posters, and A LOT of testing. We also managed to install the fully integrated system on an actual fridge!

Since most of the individual work has already been completed, most of our time this week was spent testing our integrated system together and ironing out bugs with the CV, front-end and back-end side. Besides this, we also worked on the final presentation and poster. Both the presentation and the poster seems to have turned out well, and we’re really excited for the final demo and to see how the project fares overall!
Next week, we will continue to work on the final video and poster. However, testing has also revealed some improvements and features that we could add, both on the frontend side (related to UX design like button sizes/placement), and the backend side (email notifications). That being said, we are ahead of schedule (now making reach goals and extra features, i.e. non-essential), and are really excited for our final demo and video!!!
Alex’s Status Report 4/30
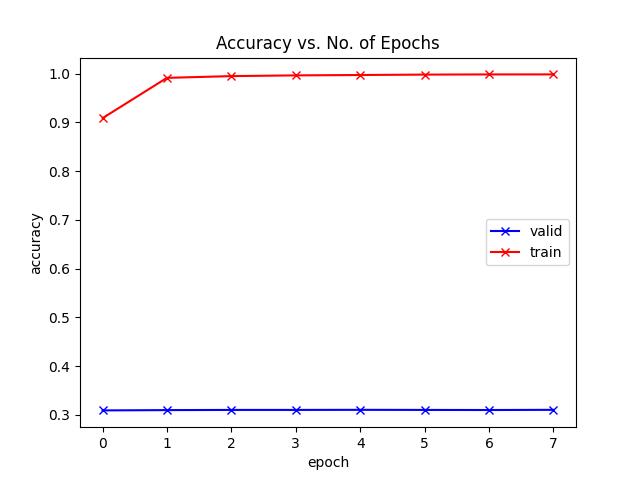
This week, I finished the final project presentation and watched everyone else’s presentations. For our project, I also worked on attaching the mechanism to the fridge, and training a new network based on the data Samuel collected. The new network still seems to be struggling (as the last one we tried did) on the custom data we collected with a validation accuracy of 30%. If we aren’t able to figure out the bug, we will just fall back on our old network which seems to be working well.
As well as attaching the mechanism to the fridge, I got the system to auto-boot on power up and to be accessible over SSH remotely if we need to access it over the CMU-device network.
Next week, I want to work with Oliver to finish off push notifications for expiring items, as well as recipe recommendations on the front end. This should not be too hard with the existing infrastructure I already have in place. We will also work on finishing up the poster tomorrow and then film the final video. There’s a fair bit of wrap-up work to do but overall we are in great shape!
30 Apr 22 – Samuel’s Status Report
Since I had completed quantity detection last week, I had nothing much left to do for the CV side of the project, besides testing and experimenting with model training/data collection, which I did. I also helped out with the installation of the system onto an actual fridge:
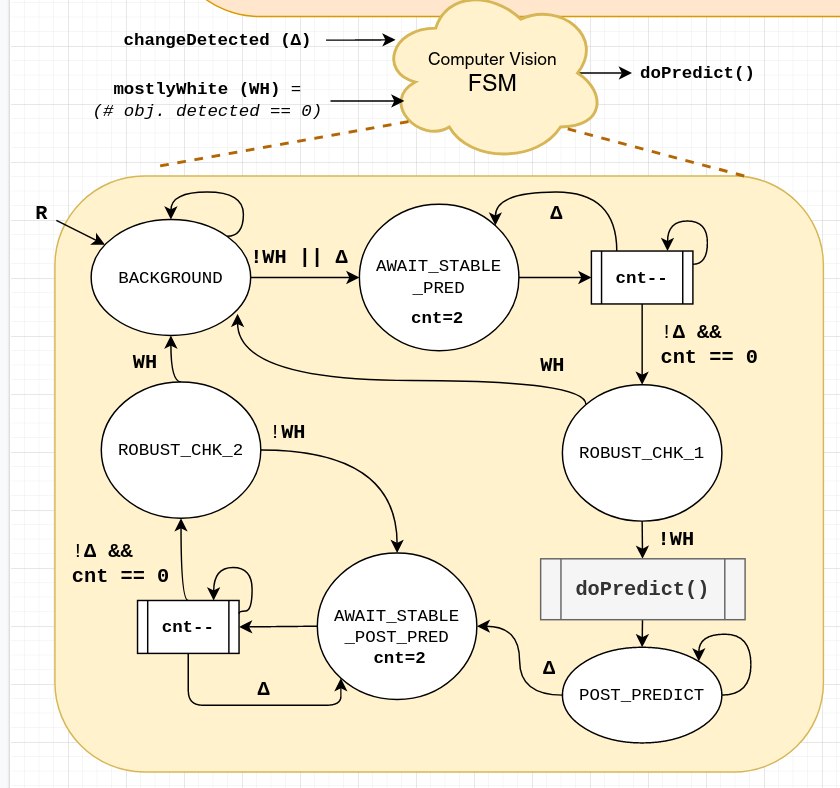
During testing, I found some edge and potential failure cases, and added more robustness checks. In particular, by using my white background detection, I fixed an issue where the FSM will move into the wrong state if the user tries to remove fruit one-by-one off the fridge, or tries to add more fruit once a prediction is done. The final FSM is shown in the Figure below:
I also trained the model again with some new fake fruits but the validation accuracy was still poor (although training accuracy was good). From the graph shown below, it seemed that the CNN was not learning the underlying model of the fruits, but was instead overfitting to the model. Most likely, this was the result of not having enough data to learn from for the new classes, thus creating confusion between fruits.

Next week, the focus will be on final testing on the integrated system (although we have actually tested quite a bit already, and the system seems to be fairly robust), and preparation for the final video and demo. CV wise, we are definitely ahead of schedule (basically done), since increasing the number of known fruits/vegetable classes was somewhat of a reach goal anyway.
Oliver’s Status Report – 23 Apr 2022
It turned out that the fix applied last week on the backend relating to items not being properly decremented upon removal was incomplete, and there were still edge cases. Thankfully, this was uncovered during further testing and integration this week, way in time before the final demo. This bug has now been fixed (and verified through the same rigorous testing process) through a complete rewrite of the item quantity computation logic. In short, instead of returning a single result after one pass through the transactions, it now makes 2 passes in order to properly account for item returns. In terms of time complexity, both approaches have a complexity of O(n), so there should be no significant difference in backend latency as a result of the change. In exchange, not only is the bug fixed, but the logic and code is also much more clearer and readable, significantly helping in any future efforts to expand the backend.
I have also made the backend more robust against incorrect quantity data, e.g. “removing” more apples than there are in the fridge. In essence, the backend now computes as if there is a floor of 0, instead of going into negative numbers, which is not logical. We passed over this aspect of the project initially as we prioritized producing new features that are suitable for the demo, but the time is now right for this change to be implemented as the product matures.
My main priority this weekend is to produce and complete the final presentation for our project. I recorded several video demos that I intend to incorporate into the slides, and collected a series of performance and benchmarking data to compare against our use case requirements (good news: we’re meeting them!)
Coming up, the largest priority is to complete the wrap up of the project as the semester comes to a close, in the form of the final presentation, poster, and final demo. We also intend to expand user friendliness and productiveness even further by allowing the user to select multiple fruits in one confirmation, based off our discovery that the CV is capable to predicting all 3 different types of fruits when all 3 of them are placed on the platform.
We’re comfortably ahead of schedule! The project including the hardware is now all in place, integration tests are nearly complete, and the semester is coming to a close. This will mark a great end to our CMU careers!
23 Apr 22 – Team Status Report
We made quite a bit of progress this week with our project, and are actually mostly prepared for a demo already 😀 We will focus our efforts on simple incremental changes + lots of testing.
We have thus far:
-
- Integrated the entire system with our tablet + Jetson
- Completed a benchmark accuracy and speed test
- Did extensive full-system bug-testing and fixed some bugs in our back-end code with returns and made the system more robust against incorrect quantity data (e.g. removing more fruits than there are in the fridge)
- Completed training of self-collected classes, including bell peppers, and are potentially looking at adding more classes.
- Debugged and fixed classification speed issues on the Jetson
- Spray-painted the background white to improve algorithm accuracy
- CV algorithm is now more robust against “false triggers”
- Nutritional information now available to user

That being said, we have found out some interesting findings and possible improvements that we can make to our project that will make our product even more refined:
- Adding email or in-app notifications to remind the user that their food is expiring soon (backend + frontend)
- Quantity detection using simple white background thresholding and GrabCut (CV, backend interface already in place)
- Different fruit type selection (see Figure above) (frontend + CV)
- Smart recipe detection
- EVEN MORE TESTING TESTING TESTING.
We are currently comfortably ahead of schedule but will keep pressing on in refining our final product 🙂
23 Apr 22 – Samuel’s Status Report
This week, we focused on integration and testing, and I also made some minor improvements to the CV algorithm, and attempted to collect more data for training.
Integration with Jetson
The Jetson was surprisingly annoying and difficult to setup, and I spent at least 10 hours just trying to get my CV code to run properly on the Jetson. In particular, trying to install various dependencies like PyTorch and OpenCV took a long time; we needed to compile a lot of dependencies from source (which came with a lot of its own errors) because the Jetson is an ARM aarch64 system which is not compatible with the x86_64 architectures that most things are precompiled for. The various issues were compounded by the fact that the Jetson was slightly old (using older version of Ubuntu, low RAM and memory capacity).
Even after I/we* managed to get the code up and running on the Jetson, we had significant problems with the speed of the Jetson system. I/we at first tried various methods including turning off visual displays and killing processes. Eventually, we realized that the bottleneck was … RAM!!!
What we discovered was that the Jetson took 1-2 minutes to make its first prediction, but then ran relatively quickly (~135ms) after that. This is in comparison to my computer which runs a single prediction in ~30ms. When Alex was debugging with a display of system resources, we eventually pinpointed the issue to being the lack of sufficient RAM when loading and using the model for the first time: the model was just too big to fit into RAM properly, and a major bottleneck came from having to move some of that memory into SWAP. Once that was complete, the algorithm ran relatively quickly. However, because it is nonetheless using memory accesses (swap) instead of the faster RAM, the predictions on the Jetson still ran slower than that of my computer. Nonetheless, it still runs fast enough (~135ms) after this initial “booting” stage, which has now been integrated as part of the “loading” in my CV code.
*while I was in charge/did most of the debugging, my teammates were also instrumental in helping me get it up and running (it is after all, Alex’s Jetson), so credit should be given where it is due 🙂
CV Training
While trying to fix/install dependencies on the Jetson, I had also in parallel attempted to collect some more data with the new fake fruits that came in, including the addition of a new “Lemon” class. However, our model could not converge properly. I believe that it was due to the fact that some of the fake fruits/vegetables were not very high-quality, and looked fairly different from the ones in the original dataset (and in real life) like the peach and pear, so when validating against our original test images, it failed to perform very well. Next week, I aim to try training only the fake fruits/vegetables that look realistic enough (like the apple, lemons and eggplant). That being said, the algorithm already performs very well against some of the semi-realistic fake fruit, like the starfruit and banana shown in Figure 1 below.
During testing, I was actually pleasantly amazed by the neural network’s ability to detect multiple fruits despite being a classifier, and outputting probabilities associated with those fruits. As can be seen in Figure 1 below, the fruits being captured are Apple, Banana and Starfruit, which appear as the top 3 probabilities on the screen, as detected by the network.
Figure 1: Multiple Fruits Detection
Minor Improvements – White Background Detection
After spray painting the platform with Alex, we now had a good white background to work with. Using this piece of information, I was able to have a simple (and efficient) code that detects whether the background is mostly white using the HSL image representation, and checking for how many pixels are above a certain threshold.
Since my algorithm currently uses changes in motion (i.e. pixel changes between the frames) to switch from different states (background, prediction, wait for user to take off their fruit) in my internal FSM, this white background detection adds an important level of robustness against unforeseen changes, like an accidental hand swipe, lighting changes or extreme jerks to the camera. Otherwise, the CV system might accidentally go into a state that it is not supposed to, such as awaiting fruit removal when there is no fruit there, and confuse/frustrate the user.
Future Work
We are currently far ahead of schedule in terms of what we originally wanted to do (robust CV algorithm, fruit + vegetable detection), but there are a few things left to do/try:
- Quantity detection: This can be done by using white background segmentation (since I already have some basic algorithm for that) + floodfill to have a rough quantity detection of number of fruits on the platform. Right now, our algorithm is robust to multiple fruits, and there is already an API interface for quantity.
- Adding more classes/training: As mentioned above, I could try retraining the model on new classes using the fake fruits/vegetables + perhaps some actual ones from the supermarket. Sadly, my real bell peppers and apple are already inedible at this point 🙁
Alex’s Status Report 4/23
This week, I worked on finishing some UI fixes and integrating everything together. First, I finished the nutrition information popup:

Then, Samuel and I spray painted the platform for better visibility. The computer vision algorithm improved drastically with the nicer white background.
Next, I set up the Jetson for the computer vision processing. We had a lot of issues with performance, but I discovered that when I disabled all of the GUI processes, the performance improved slightly. We wanted to improve performance using Tensor RT, but I found it very hard to compile (resource limited and arm processor) and no precompiled binaries were available. Fortunately, disabling the GUI was enough to improve performance, but it appears that there is a bug with torchscript that causes the performance to be extremely slow on the first detection. After “warming up” it seems to perform much better, so we will account for this in the code. My hypothesis is that the CPU needs to optimize what goes in the swapfile since it has to use about 1 GB of swap to run the process, which is significantly slower than RAM.
Finally, I tested the performance of the algorithm and we worked out a few bugs on the API and made sure that we are in good shape for the demo. I also collected detection times for our performance evaluation. I then worked on putting all this data into the final presentation.