Accomplishments this week
1. Advanced MIDI pattern matching.
- This week I made several test cases to test the bag-of-words approach by randomly delete some notes from the original slices. The testing procedure is (1) slice the original midi file, called ori_midi, into slices of different lengths, called ori_slice (2) randomly delete range(5, 60, 5) percent of notes from the ori_slice, called test_slice (3) use a sliding window, whose length equals len(ori_slice), to loop from each note in ori_midi and try to match the window with the test_slice (4) return the offset of the window which has the smallest Euclidean Distance between itself and test_slice.
- MIDI files generated with different percentages of missing notes: original midi file, test slice with 5% notes missing, test slice with 20% notes missing, test slice with 30% notes missing, test slice with 50% notes missing. The melody is still human-recognizable when below or equal to 30% of the notes are missing, yet a human can hardly tell if the test slice is generated from the original slice when the percentage of missing notes is higher than 30%. Thus, I think it’s safe to assume that the player should not be playing with an error rate higher than 30%.
- I tried both Bag-of-Words with and without normalization, and the normalized version provides better results than the un-normalized version, yet the result is still not promising for the purpose of this project. Snapshots of the statistics is shown below:
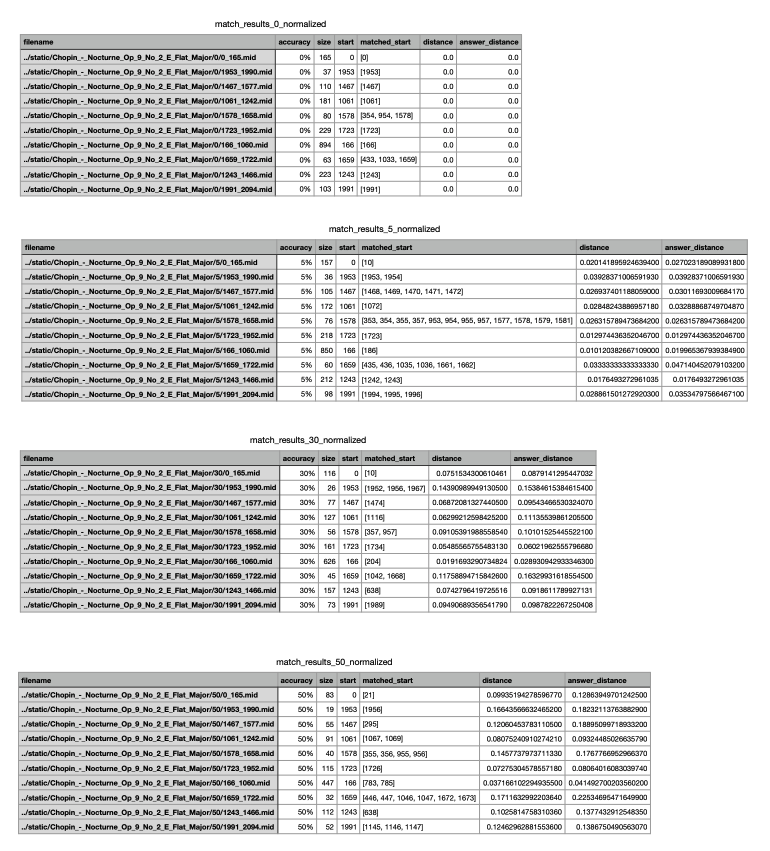
- Bag-of-Words tend to match nearby measures, which is not the behavior we want. Thus, I decide to move on to the Levenshtein distance. Since I force the sliding window to have about the same size as the test_slice, Levenshtein distance should be a good choice to calculate the difference between two midi slices here. Since several notes are pressed at the same time while playing the piano, I decided to only extract the note with the highest pitch. I adopted the algorithm from this paper:

- I’m still in the process of developing this algorithm.
2. Manual Labelling of Flip/Repeat Points.
- I’m trying to see if this can be done in a programmatic way. I’ve found resources here and here which seems to be good solutions to what I’m trying to fulfill.
- I’m planning to move on to manual labeling if I cannot get the above approaches to work next week.
Progress for schedule:
- On schedule
Deliverables I hope to accomplish next week:
- Finish the Levenshtein Distance algorithm
- Try out the computer vision approaches linked above / start manual labelling of the flip/repeat points
0 Comments