This week I finalized the simulation for the laser line camera input. I experimented with a few more objects and I also tuned the laser strength. Our laser line was previously too thick as shown below:

How the laser is currently being projected is that it is actually a light source projecting a black image with a thin white line in the middle added with a red tint. The current render setup is as follows:
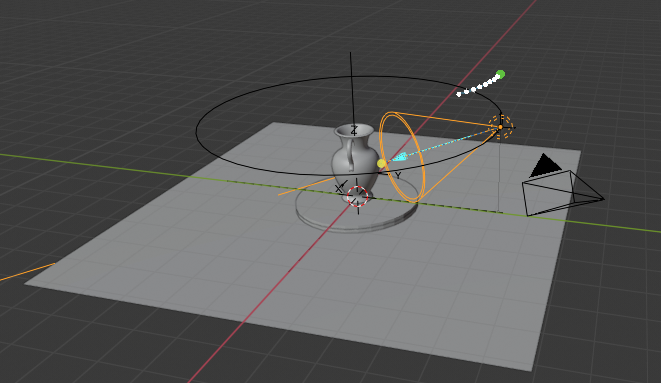
The orange selected cone is the laser projection source, and the object on the right with the triangle on top is the camera. The laser is currently at a height of 25 cm and I manually adjusted the laser to be able to cover the tallest allowed object which would be 30 cm tall. The camera is at a height of 40 cm and a 45 degree offset from the laser, at coordinates (70, 70, 40). The laser is at (0, 40, 25). After tuning the strength of the laser projection as well as the width, I obtained this render:

This was obtained at 32 samples meaning there are 32 samples per small box that Blender renders at a time (using Cycles Render). If we look closely (not sure how good the image will upload in WordPress) we can see some tiny red dots scattered around the image, and the laser line is also not crystal clear. This is due to Blender estimating some of the light bounces since we are sampling at such a low rate for the render. This can be fixed by bumping up the samples, as shown here with 512 samples.

Our current light bounces is set to 1 to be realistic yet not cause too much diffuse in the render, and I can also control how much the laser glows. We can actually use a low sample rate to generate noise in a sense, and perhaps increase the number of light bounces to add more noise into the image. With 256 samples and 10 light bounces, we can start to see some red noise near the laser line (again I’m not sure how well images upload to WordPress):

I also tried some other objects like this Pokeball but we will probably stick with the vase above for the in-lab demo.

One big cost is rendering time – especially with our original design where we would have 2000 frames, currently each frame with 32 samples only takes 8 seconds to render. This adds up to 16,000 seconds = 4.44 hours for 2000 frames. Thus, in terms of the user story, we will probably allow users to pre-select scanned images to demo. We will likely reduce the amount of frames as long as we can maintain a reasonable accuracy number. I was considering increasing sample rate and lowering the number of frames to get less noise per image, but I think keeping that noise in allows us to simulate what the real world image would’ve been like better.
Our render resolution is 720p to simulate that of our original USB webcam. We will use 1 light bounce for our in-lab demo since we haven’t fully developed and tested our noise reduction for the images yet.
Our current render parameters are:
| Resolution |
1280 x 720 (720p) |
| Samples |
32 |
| Light bounces |
1 (initial development), 10+ (trying out noise reduction later) |
| Frames |
30 (developing algos), 2000 (full test) – may likely change |
| Laser position (cm) |
(0, 40, 25) |
| Camera position (cm) |
(70, 70, 40) |
| Max object size (cm) |
30 x 30 x 30 |
| Render quality |
80% (more realistic) |
| Laser intensity |
50,000 W (a Blender specific parameter) |
| Laser blend |
0.123 (how much it glows around the laser) |
I will be helping the team finalize things for the demo the coming early week and start implementing ICP for combining scans as well after the demo.