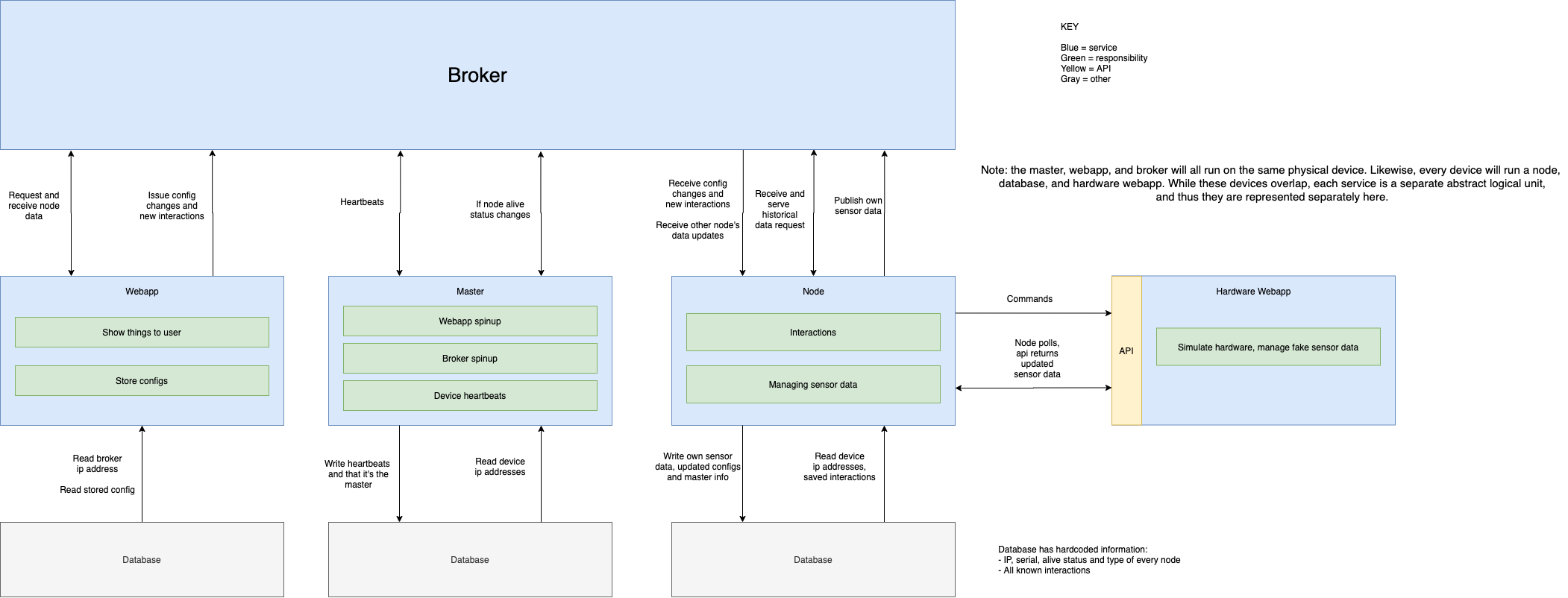
This past week, I put a lot of work into wrapping up the functionality of the interaction layer and integrating all three parts together.
The way we broke the project up, node infrastructure (aws hosting) fell under the interaction layer umbrella, since the ‘node’ process is the top level process running on the node and managing the other processes. As such, it fell onto me to take care of running the frontend webapp and making sure that the data read / write pipeline worked from the frontend all the way through the interaction layer and down to the hardware emulator for each node.
Below, I’ve broken up my work this past week into different categories, and I elaborate on what I worked on in each category.
- Infrastructure
- setup script: I changed the setup scripts for setting up a new node to create a shared Python virtual environment for the project, rather than a different one for each of the three parts. This made it much easier when manipulating different parts of the system, since I no longer had to worry about which virtual environment was being used.
- AWS
- Set up all the nodes: I created 5 unique nodes, each with a different config and hardware description. Since initial device commissioning is out of the scope of the project, when the system “starts” for any demo, it has to already be initialized to a steady state. This means I had to hardcode each device to work properly
- Elastic IPs: I figured out how to create and assign a static IP address (called an elastic IP by AWS) to each node, so that I could easily hard code the IP address within the code instead of dynamically gathering it each time Amazon decides to change it.
- Static IP for webapp: I started looking into defining an extra elastic IP address that is reserved for the webapp instead of for a specific node. The way this would work is that all nodes have a unique static IP address, but the master node has an additional public IP address pointing to it. If and when the master dies and another node promotes to master, the new master will dynamically claim that second static IP from AWS. The result of this would be that the same IP address would always point to the webapp, even if the node hosting the webapp changes. I hit a few issues, such as restarting the network stack on an Ubuntu 18.04 virtual machine, and couldn’t get this working by the final demo.
- Interaction layer
- CONFIG and hardware_description parser: I made the definition for the CONFIG file clearer and more rigid, and added functionality to easily parse it and get a dictionary. I also created a helper function to parse a “hardware_description.json” file, which describes the hardware located on the node. This was something required by Rip’s hardware emulator that I hadn’t expected, and had to be done during integration.
- Database schema updates: As discussed in last week’s update, Richard and I discussed certain updates that had to be made to the database schema. I updated the database (and database management helper functions) as per our discussion.
- help_lib for Richard’s frontend webapp: I added the following functions to a file called help_lib.py, with the intent that these would facilitate communication between the webapp’s backend and the interaction layer’s distributed data storage.
- addInteraction: takes a new interaction and sends it to all nodes in the system to write to their database
- deleteInteraction: same as addInteraction; deletes an interaction on all nodes in the system
- updateInteraction: same as above, but updates an interaction in place instead of deleting it. The way the frontend is currently set up, their is no way for a user to modify an existing interaction, so this function is unused.
- updateNode: update the display name and description of a node. This again makes sure to sync across all nodes
- getNodeStatus: takes a list of node serial numbers, and for each node, gets the current value of that node, from the node, through the mqtt broker. If the node is dead, will short circuit and return that the node is dead, instead of trying to ping it to ask for a status update
- setStatus: set the value for a particular node. E.g. turn a light on, set off an alarm, etc. This will communicate to that node through the broker.
- db_lib for sql interactions (read / write etc): added a lot of functionality to the db_lib file for managing the database, so that code outside the db_lib file has to do minimal work to read from / write to the database, and in particular, has to do nothing relating to sql.
- Proper logging setup: updated the logging in the system to use the python logging module and create logs useful for debugging and system monitoring.
- MqttSocket: created a new class called MqttSocket (i.e. socket type functionality over mqtt). Currently only used by getNodeStatus, this class is meant to describe and facilitate a handshake type interaction between two nodes. We decided to do all node communication through the broker instead of directly from node to node in order to facilitate interactions. However, sometimes one node has to specifically request a piece of information from another node, which follows a request / response pattern. The async and inherently separated publish / subscribe nature of MQTT makes it fairly convoluted to follow this request / response pattern, so I packaged the convoluted logic into a neat helper class that makes it very easy to do the request / response cycle. Here is an example of how it’s used:sock = MqttSocket()# topic to listen for a response
sock.setListen(‘node/response’)# blocking function, sends ‘data’ to ‘node/request’ and returns the
# response sent on ‘node/response’
sock.getResponse(‘node/request’, data)sock.cleanup()
- Master failover: master failover hinges on the fact that nodes know whether other nodes in the system (in particular the current master) are alive. Initially, I planned to do this using regular heartbeats. However, I realized that the mqtt protocol has built in support for exactly this behavior, namely topic wills and on_disconnect callbacks.
- topic wills: any client that connects to a broker can define a ‘will’ message to be sent on any number of topics. If the node disconnects from the broker without properly sending a DISCONNECT packet, the broker will assume it died and send its will message to all nodes subscribed to that topic. I used this to implement heartbeats. All nodes listen to the “heartbeats” topic, and if a node dies, they will all be notified of its death and update their local database accordingly. If the master dies, this notification is done using the on_disconnect callback.
- on_disconnect: if the underlying socket connection between the paho mqtt library (the library I’m using for client-side mqtt behavior between the nodes and the broker) and the broker is broken, it will invoke an optional on_disconnect callback. This callback will be invoked any time the node client disconnects from the broker. However since the nodes should never intentionally disconnect from the broker, this will only happen if the broker has died. This way, nodes are notified of a master’s death, and can begin the failover process.
- By using topic wills and on_disconnect, I save needing to send frequent publishes from each node, which would cost unnecessary bandwidth. If a node receives notice that the master has gone down, it will select a new master. The next master is the node with the lowest serial number of the nodes that are currently alive. If that happens to be the current node, it will start the master process, otherwise, it will try to connect to the broker on the new master node.Currently, all of the above works except for the final reconnect step. For some reason, the client mqtt library is having trouble throwing away the previous connection and connecting to the new broker. As such the failover happens, but nodes can’t communicate after :(. I will fix this before the “public demo”.
- populate db: while hardcoding is generally frowned upon, since our system has a “stable state” for demos, I needed an easy way to get to that steady state. I made a script that populates the database with the hardcoded node values as they exist in the defined steady state, so that it’s very easy to reset a database’s state.
- Path expansion for integration: this was a small bug that I found interesting enough to include here. On the node, the top level directory contains three repositories:hardware-emulator, interaction-layer, and ecp-webappThe helper functions I wrote for Richard’s frontend exist ininteraction-layer/help_lib.pyand those functions are used inecp-webapp/flask-backend/app.pyMore importantly, those helper functions use relative paths to access the config and database files, which creates problems when the webapp tries to call them. I had to change this behavior so that the helper lib expands relative paths to absolute paths, allowing them to be called from anywhere in the systm.
- interactions: interaction definitions were ironed out to work with the way the hardware emulator expects values to be, and how the frontend expects them to be. Since my layer is in the middle, I had to be careful about parsing, storing, and acting upon interactions.
- Problems to be fixed this upcoming week:
- broker failover: as discussed above in the master failover section, after a master failover, nodes fail to reconnect to the new broker. This needs to be fixed.
- conflicting interactions: the frontend allows you to define conflicting interactions, which would arbitrarily thrash the system. For example, I could define the following 2 interactions:
if motion sensor > 5, turn light on
if motion sensor > 5, turn light offNow, if the motion sensor is triggered, the light will begin rapidly flickering, which is annoying and probably unintended. I think it would be cool if the frontend can identify such conflicting interactions, but it may end up being far more complicated than I suspect, and might be too hard to identify loops.
- setting sensors on frontend: the frontend currently allows you to set a value for any device, such as setting “light = 1” (turn on the light). However, if you try to set a value for a sensor node, the backend throws an exception, crashing the interaction layer. This behavior needs to be prohibited.
- measure latency: in our design docs, we defined latency requirements. While the logging facilities are in place to measure this latency, we need to actually do the measurements for the final report.