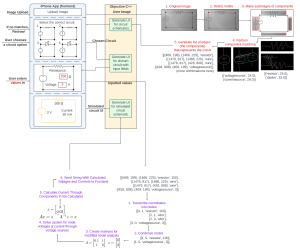
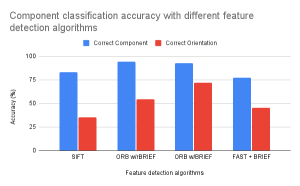
This week I researched different types of algorithms to use for feature matching in order to detect and identify individual electrical components. The two primary feature detection algorithms I considered were SIFT and ORB. From testing what I noticed was that ORB significantly handled variation in size and orientation much better than SIFT, and just had more features matching in general.
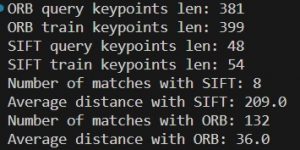
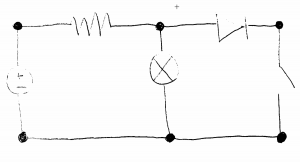
In the above photo you can see the results of using SIFT and ORB when comparing two images of resistors. ORB is clearly better with 132 / 381 matches, while SIFT only has 8 / ~48. Here is the visualization for the matches with ORB:

Note that the drawings of the resistors were first pre-processed with a contour detector that Devan found, which is why the background is entirely black and the contour of the resistors are in white.
When I tried comparing a resistor that was aligned vertically and one that was aligned horizontally, this was the result:
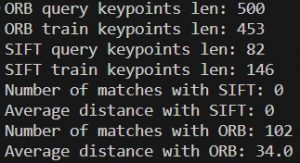
SIFT could not even generate any matches while ORB still could.
At this point I am confident that ORB is the algorithm we will use to generate FAST keypoints and BRIEF descriptors.
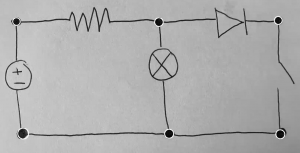
The one problem I have run into is that when using a resistor and voltage source drawing, the results of the matchings aren’t as polar as I expect them to be.
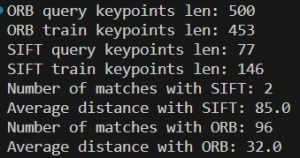
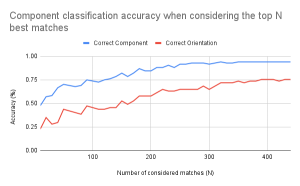
This is the result of comparing a resistor and voltage source drawing. If we compare to the matches of two similar resistors (first screenshot), we can see that ORB produces slightly less matches for the one with a resistor and voltage source. But, if we compare these results with two resistors of different orientation (second screenshot), they are pretty similar (~100 matches). While this may seem worrisome, I think that this is not too problematic because I believe the solution to this is to include various orientations of components in our training and validation datasets. This way, the matching of the same components in different orientations will be stronger and should contrast more with the matching results of two different components.
I am on schedule with my progress. I have established a good foundation with the algorithms to use for individual piece detection, and I want to continue exploring and tweaking to see if I can better improve the matching contrast with different components. Another thing I want to specifically try is using a different matching algorithm, as all of the above experiments used a brute force matcher. My steps for next week will be to create a reasonable feature vector with metrics that will be used to determine classification.