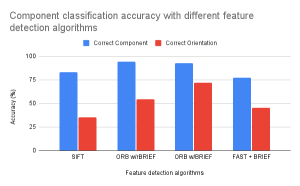
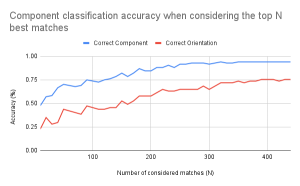
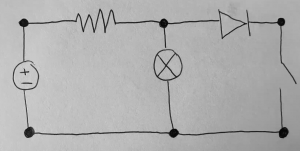
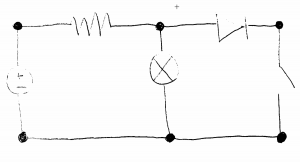
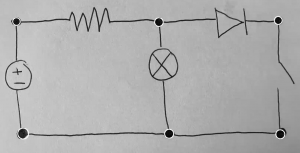
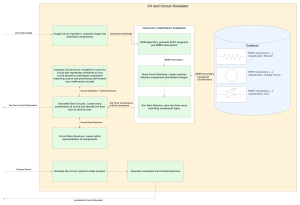
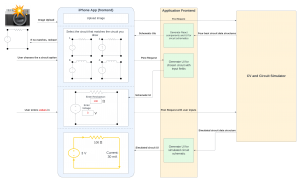
Unfortunately this week I did not get to spend as much time on testing as I wanted. Because we decided to not implement diodes, I had to get rid of their classification from the code and dataset. I also ended up spending more time on the poster than we should have, but in my defense it was to make this awesome diagram:
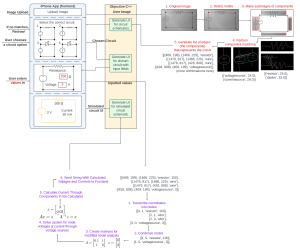
Tomorrow I am going to do a lot more testing. Unfortunately some circuit test images will need to be redrawn because they contain diodes. Interestingly I noticed from the component classification testing that current source orientations seem to be working well, but not so much voltage sources. Hopefully I will be able to identify what could be the difference and what a solution for it is. Because there are no diodes now switches aren’t getting misidentified as diodes, but there does seem to be a rare case where a resistor/switch gets identified as the other. I will look into this as well and see if I can identify another solution.
Other than this our CV is in a decent state for the demo. As long as my group members have properly finished the integration and their parts, our demo should be good to go.