This week I spent some time making changes due to hardware problems such as making it work for 2 solenoids instead of 4 solenoids and making it work for the solenoids being 3 characters apart rather than 4 and with lines that are 12 characters long. We also realized that the braille was in reverse since we are punching down so I reflected that in the translation.
I wanted to make an option for people to upload an image of a box and use the barcode to get the directions from that using cv2 and pyzbar and while I was actually able to make it work and even created html webpages and functions using Flask to integrate the entire platform, it turns out that the raspberry pi has restrictions when it comes to using the opencv libraries so it doesn’t seem like I will get around that. Since it wasn’t one of our original goals, it’s not a big deal but I am pretty disappointed because I got the entire platform to work and it was also super accessible with the iphone and Apple voiceover.
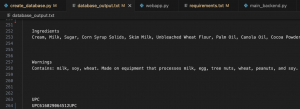
I spent the most significant portion of my time working on official testing. Throughout this semester, I have been doing basic, integration, and edge case testing and the occasional stress testing, but nothing officially put in a file. I now have a file that tested both the uncontracted and the contracted braille functions by trying 100 randomly generated strings and comparing it with the output of braille blaster. This helped me hone my algorithm further to get 100% accuracy. I also tried testing with 100 most popular products according to https://progressivegrocer.com/100-iconic-brands-changed-grocery and checked to see how many responses were in the database (97%) and also how many responses were relevant(100%). I tested the time it took for creating the database by converting it from a csv to the database multiple times and averaging that time as well as the average time it took for each query in the above test. Based on those times, the one time database cost seemed to be. more worth it. I tested the solenoid instruction generation by creating a sample input with unique numbers instead of just 0s and 1s and compared it to the expected output.
I also spend a significant amount of time working with Zeynep integrating the rpi with all of my software code with the physical hardware and while the individual components are working, we do have a bit of honing things down to go.