What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
This past week we came back together after being away on fall break. We received feedback on our design report which was overall positive and gave us a continued path forward for development. The beginning of the week was also spent initially working on the ethics assignment in preparation for class next week. In my own subsystem of the product, I continued to develop the spell checking algorithm code such that it could take in words and output the nearest real word. At the moment, it is only checking a dictionary and no probability metric is placed on words to give them a hierarchy when developing a best fit for each correction. One possible way that I researched for providing a probability is to use the Counter library in python and break down a collection of large texts in conjunction with a dictionary or large set of more often used words. This would create a hierarchy of words that are used more often, giving them a higher probability of being the replacement for the misspelled word. Lastly, I authenticated the Google API text to speech to be used on my local computer and I am currently able to generate mp3 and wav files via the API.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
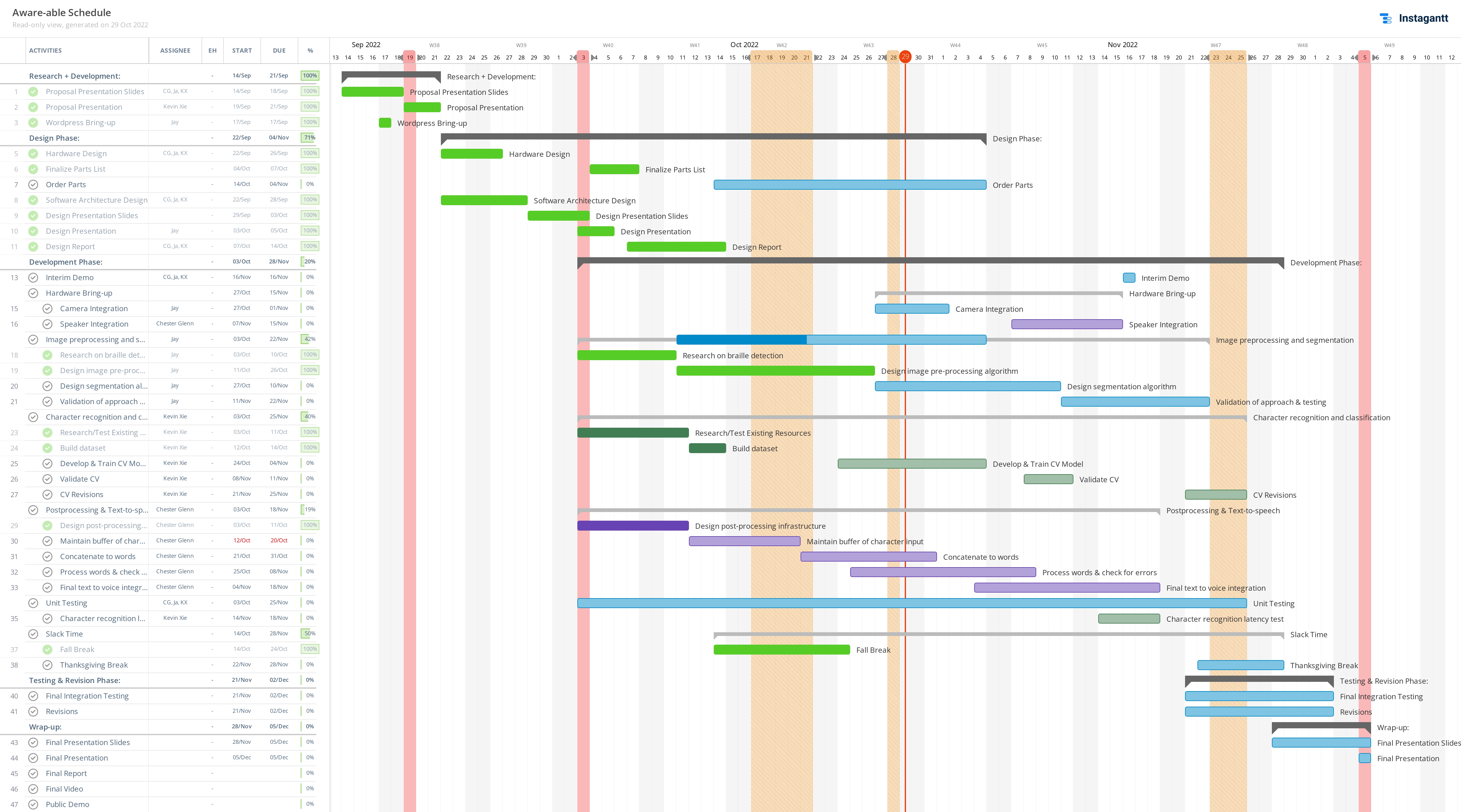
With two weeks until the interim demo, our product is in the stages of finalizing the separate subsystems of development. Our main goal is to have the separate subsystems display working functionality depicting the relative pipeline of our product. As of now, I am confident that my concatenation, algorithms, and final text to speech application is viable and will be able to perform a rough full run through within the two weeks provided in front of us.
What deliverables do you hope to complete in the next week?
In the upcoming week, I would like to start connecting the spell checking algorithm code with the google API text to speech capabilities, so I can verify the quality of the speech product, as well as start to hammer out inconsistencies in the spell checking algorithm itself. I would like to begin some formal testing of this subsystem if there is time. This is most likely going to be the integration process of the next two weeks before the interim demo.