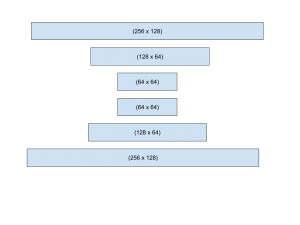
For the final two weeks of the semester I scheduled most of my time for refining the feel of using our product as well as preparing for our final presentation and public demo.
For the refining portion, I added a minor smoothing to the movement of the mouse by averaging the location of the 6 landmarks surrounding the palm of the user’s hand.
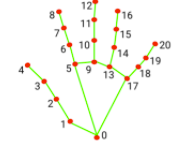
Following that, the location of the hand is averaged across 3 frames of calculation to act as a low pass filter on the noise generated by our CV system.
Further, in order to circumvent an issue with the product where it could not differentiate between a click and a click and hold, I segmented each action into its own gesture. Click and drag/holding is now the closing of the hand into a fist, while a simple click is touching your index finger to your thumb, like an ASL number 9.
Finally, in preparing for our final demo and presentation I spent a few hours running experiments involving different model architectures and data augmentation to provide reasonable insight into tradeoffs and design decision outcomes.