
I spent this week experimenting with various model architectures and training them with our formatted data.
Each model has 42 input features, representing an x and y coordinate for each of the 21 landmarks, to which it assigns one of 26 possible labels, each corresponding to one class or variant of gesture.
In a paper titled “Gesture Recognition Based on 3D Human Pose
Estimation and Body Part Segmentation for RGB
Data Input” various architectures for a problem similar to ours were tested, with much success coming from architectures structured as stacks of ‘hourglasses.’ An ‘hourglass’ is a series of fully connected linear layers that decrease in width and then increase out again, with the heuristic behind this being that the reduction in nodes, and thus the compression of information regarding a gesture, would reveal features of the model that would then be expanded again to be repeated.
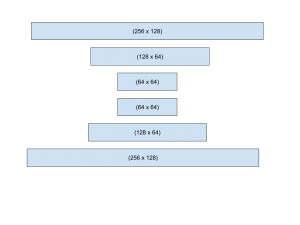
Using this stacked hourglass architecture I experimented with architectures, including ‘skip’ connections that would add the inputs from compression layers (where output features are lower than input features) to decompression layers to allow information that was lost in compression to be available if needed.

I also experimented with the number of hourglasses that were stacked, the length of each hour glass, and the factor of compression between layers. Along with this, multiple loss and optimization functions were considered, with the most accurate being cross-entropy loss and Adagrad.
The most effective model found thus uses only two hourglasses of the structure pictured above, achieving a validation accuracy of 86% after being trained over 1000 epochs. The training loss over 350 epochs is pictured below.

I will spend the rest of this weekend preparing for the interim demo for next week, and next week will be spent presenting said demo. Along side this further model experimentation and training will be performed.