The most significant risk is the integration of the PCB. Because we collected training data from the glove when the ARDUINO was attached to the protoboard, some of the IMU data was adjusted for data similar to that. Right now, we are hoping that by fixing the PCB case more securely on the glove, we can hopefully fix accuracy issues. The contingency plan is to reattach the protoboard which we are sure works.
There are no major changes at this stage.
There are no schedule changes at this stage.
The ML model had a unit test where we evaluated performance by seeing the accuracy on a separate test set. We were content with the performance as the model always had a performance of above 97% on different subsets of the data.
The ML model also had a unit test for latency using Python’s timing module. This timing system almost always reported an infinitesimal amount of time, so we were happy with the performance.
We also had some unit tests for the data that entailed looking over the flex sensor readings and comparing them to what we expected. If they deviated too much, which was the case for a few words, we took the time to recollect the data for that word or simply removed outlier points.
Overall accuracy was tested by having us sign each word in our selected vocabulary 12 times each in random order and evaluating the number of times that it was correct. Initially, performance was rather poor at around 60% accuracy. However, after looking at the mistakes and developing a smaller model for easily confused words, we were able to bump performance up to around 89%.
Overall latency was tested at the same time by calculating the time difference from the initial sensor reading until the system prediction. With our original classification heuristic, the time it took was around 2 seconds per word which was way too slow. By changing the length of predictions it needs, we were able to bring overall latency down to around 0.7 seconds which is closer to our use-case requirement.
As for sensor testing, we would take a look at the word prior to data collection, and then manually inspect the data values we were getting to ensure they corresponded with what we expected based on the handshape. For example, if the sign required the index finger and thumb to be the only two fingers bent, but the data vector showed the middle finger’s flex sensor value was significantly low, we would stop data collection and inspect the circuit connections. Oftentimes a flex sensor had come a little loose and we would have to stick it back in to get normal readings. In addition, post data collection we would compare the feature plots for all three of us for each sign, and make note of any significant discrepancies and why we were getting them. Most often it would be due to our hand sizes and finger lengths being different, which is to be expected, but occasionally there would be feature discrepancies that indicate someone was moving too much or too little during data collection, which would then let us know that we should recollect data for that person.
In terms of haptic feedback unit testing, we wrote a simple Python script and Arduino script to test sending a byte from the computer to the Arduino over Bluetooth, and whether the Arduino was able to read that byte and create a haptic pulse. Once we confirmed this behavior worked through this simple unit test, it was then easy to integrate this into our actual system code.


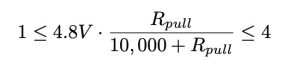
 . Lastly, I finished all my tasked sections for the Design Report that was due last Friday.
. Lastly, I finished all my tasked sections for the Design Report that was due last Friday.