As stated in last week’s report, I spent a lot more time on the recommendation system this week. I worked to improve the recommendations from a single song, and then also implemented the session recommendations as well. I will describe both in detail:
Recommendation From Song:
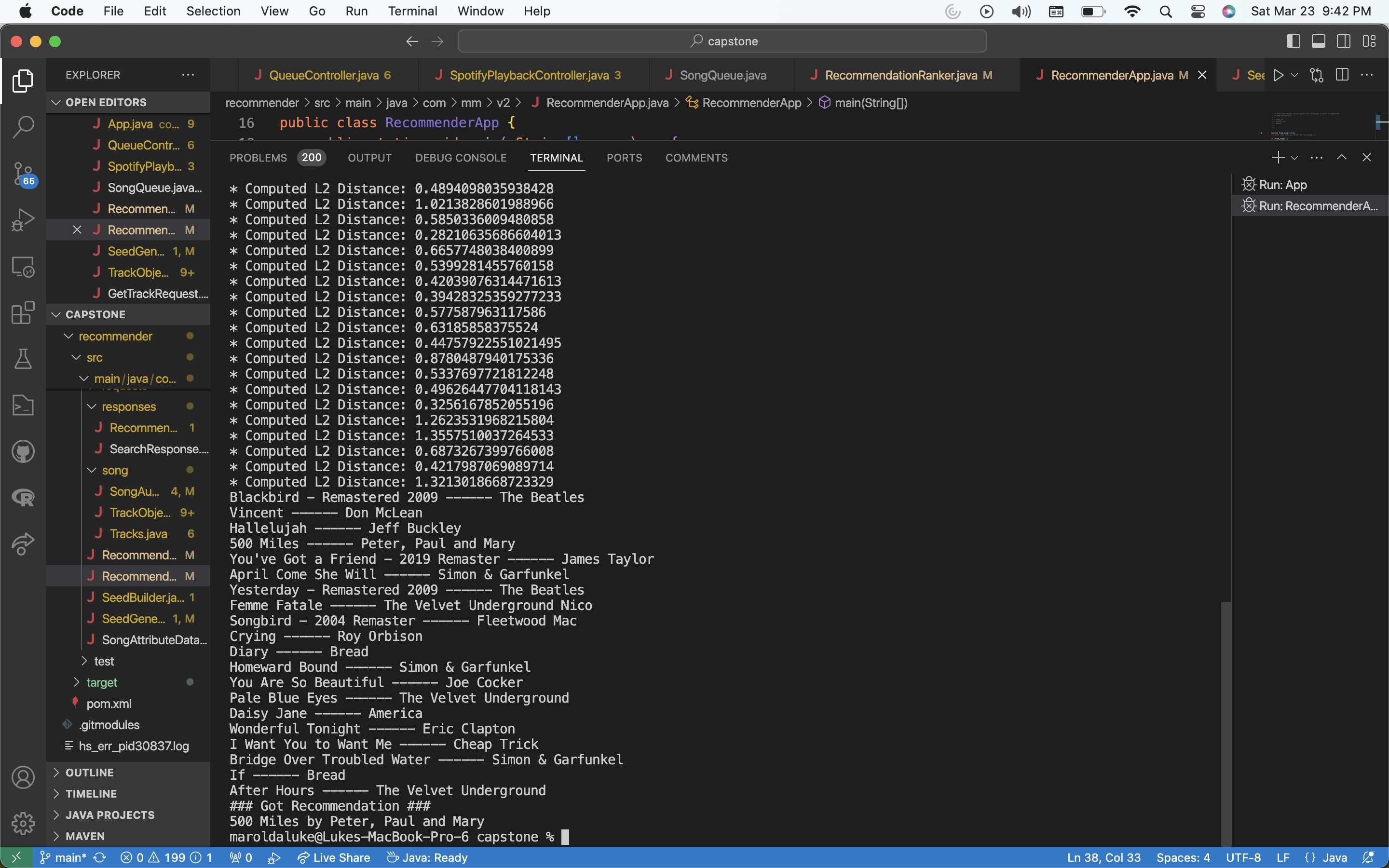
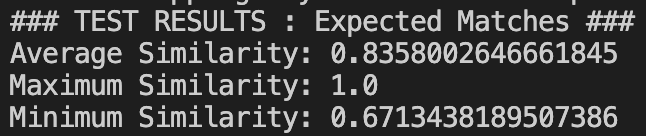
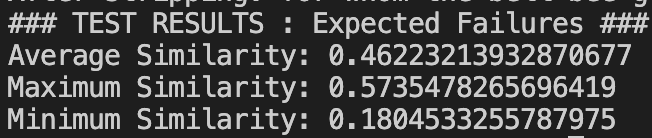
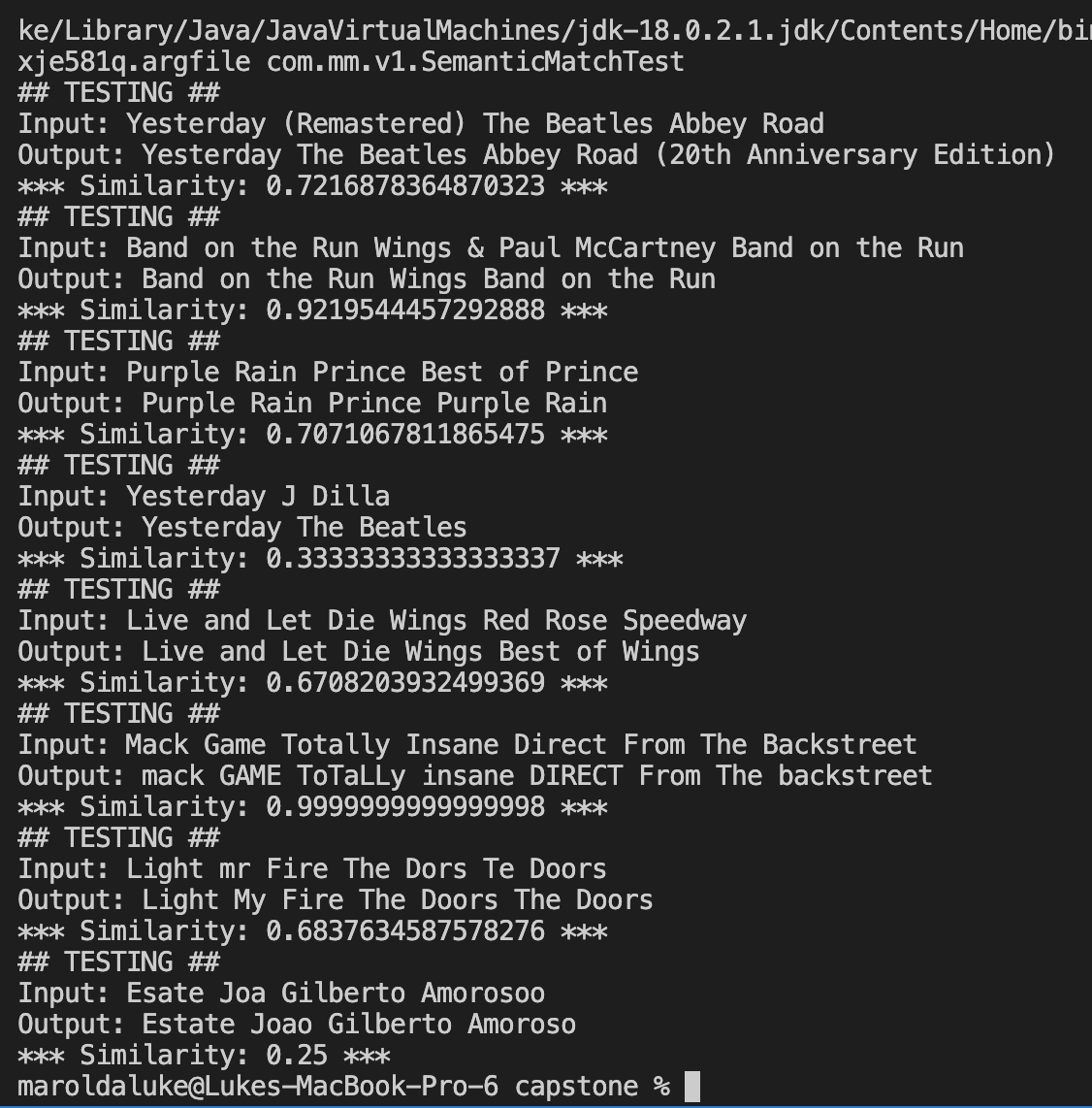
In the last post, I described how I actually generated a seed to then use Spotify’s recommendation endpoint to get a list of recommendations. But now, we want to improve further on Spotify’s recs to ensure the user gets the best possible recommendation. So this is where I had some fun. At this point we have two things: an input song, and then a list of recommended song’s Spotify returns. We want to determine which of these songs to return, which is ideally the one most similar to the input song. Now also consider that as mentioned before, we have many song characteristics available to make this decision. So, I narrowed the parameters to the values that are actually meaningful when comparing two songs, and have the following 9 characteristics: acousticness, danceability, energy, instrumentalness, liveness, loudness, speechiness, tempo, valence. So now, let’s treat each ‘song’ as a point in a 9-dimensional vector space. Our problem described above, now simplifies to choosing the recommendation that minimizes the L2 norm with the original input song (or another distance metric). Thus I implemented this exact described process in code and now we can successfully further refine Spotify’s initial recommendations, with an output that more closely matches the input.
Session Recommendation:
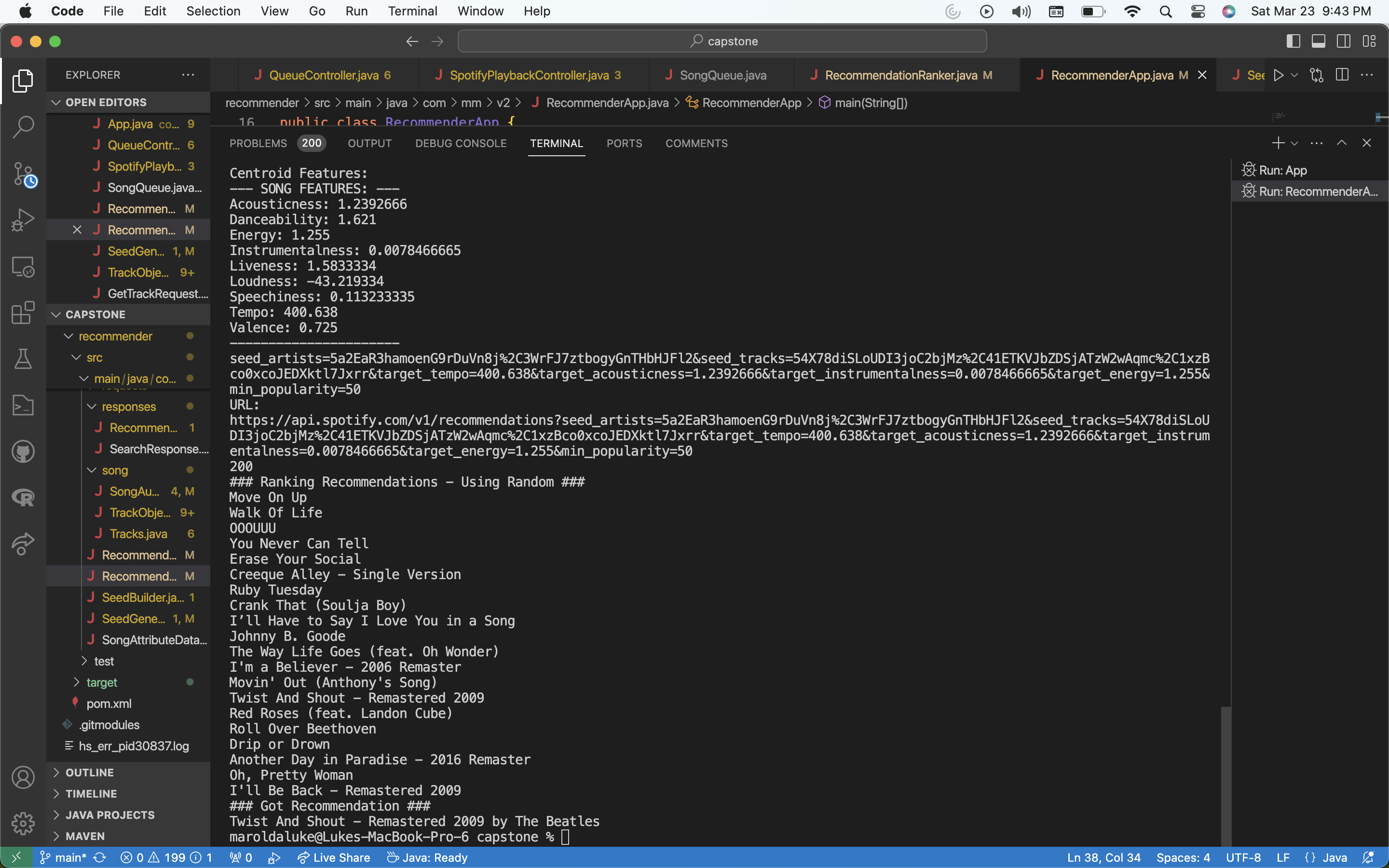
Now, we also want to support the functionality of a generic ‘session’ recommendation – recommendation that takes in all of the songs that have been played into account. As discussed before, we can do this in a smarter manner because we have access to user feedback: the likes and dislikes a song has received at the event. So the problem simplifies to, given a map of played songs and their number of likes, generate a song recommendation. Mainly, how can we translate this information into a Seed to send to Spotify’s recommendation endpoint. This boils down to two things: compiling the seed songs and artists and then choosing the song characteristic values for the seed. For the former, we can sort the session songs based on their likes, and then just choose the 3 song_ids of the top 3 songs and then the 2 artists of the top two songs. This gives us the needed 5 params for the seed in terms of song and artist. Where things get more interesting is selecting the numerical values for the song characteristics in the seed. An initial idea is finding the geometric average (ie. the centroid) of the input songs in this 9-dimensional vector space I talked about earlier. But this creates dull values. Think about the case of 3 session songs, each being drastically different. if we just take the geometric mean of these songs’ characteristics vectors, then we’ll just get song attributes that don’t resemble any of the songs at all, and are just a bland combination of them. So instead, we compute the weighted centroid, which is the weighted geometric sum where each weight is the number of likes corresponding to each of the songs. Then, we use this resulting weighted centroid as the input to our seed generator. This works well which is great
The next interesting question in this realm is doing the same thing we talked about for the single song rec. Once we get recommendation results from Spotify, how do we further refine to get the best possible recommendation. This is something that is not urgent but it’s super interesting so I’ll spend time on it in the coming weeks. What I rlly want to do is K-means cluster the session songs and then choose a recommendation result that minimizes the L2 norm from any of the cluster centroids, but that’s a bit over the top. We’ll see
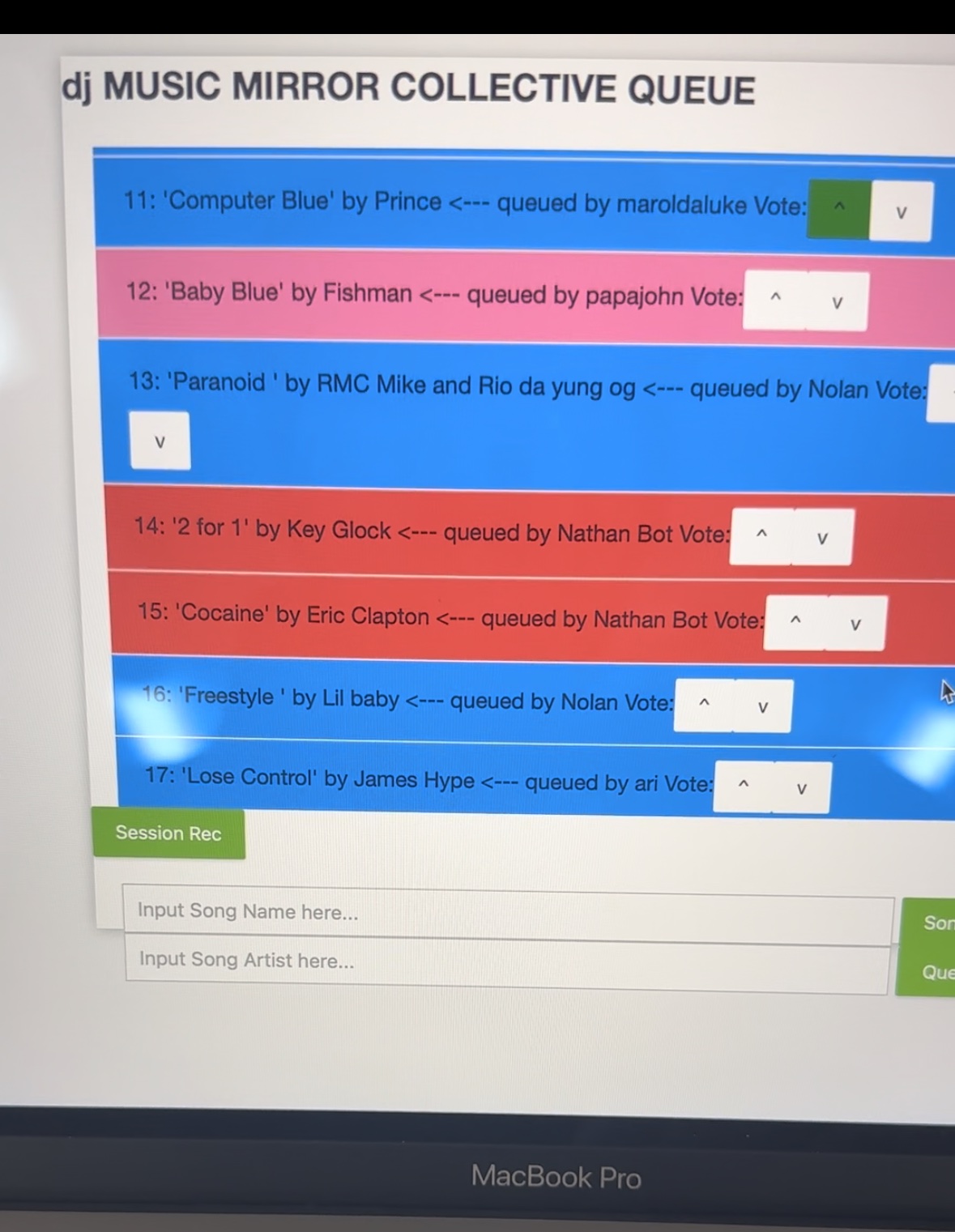
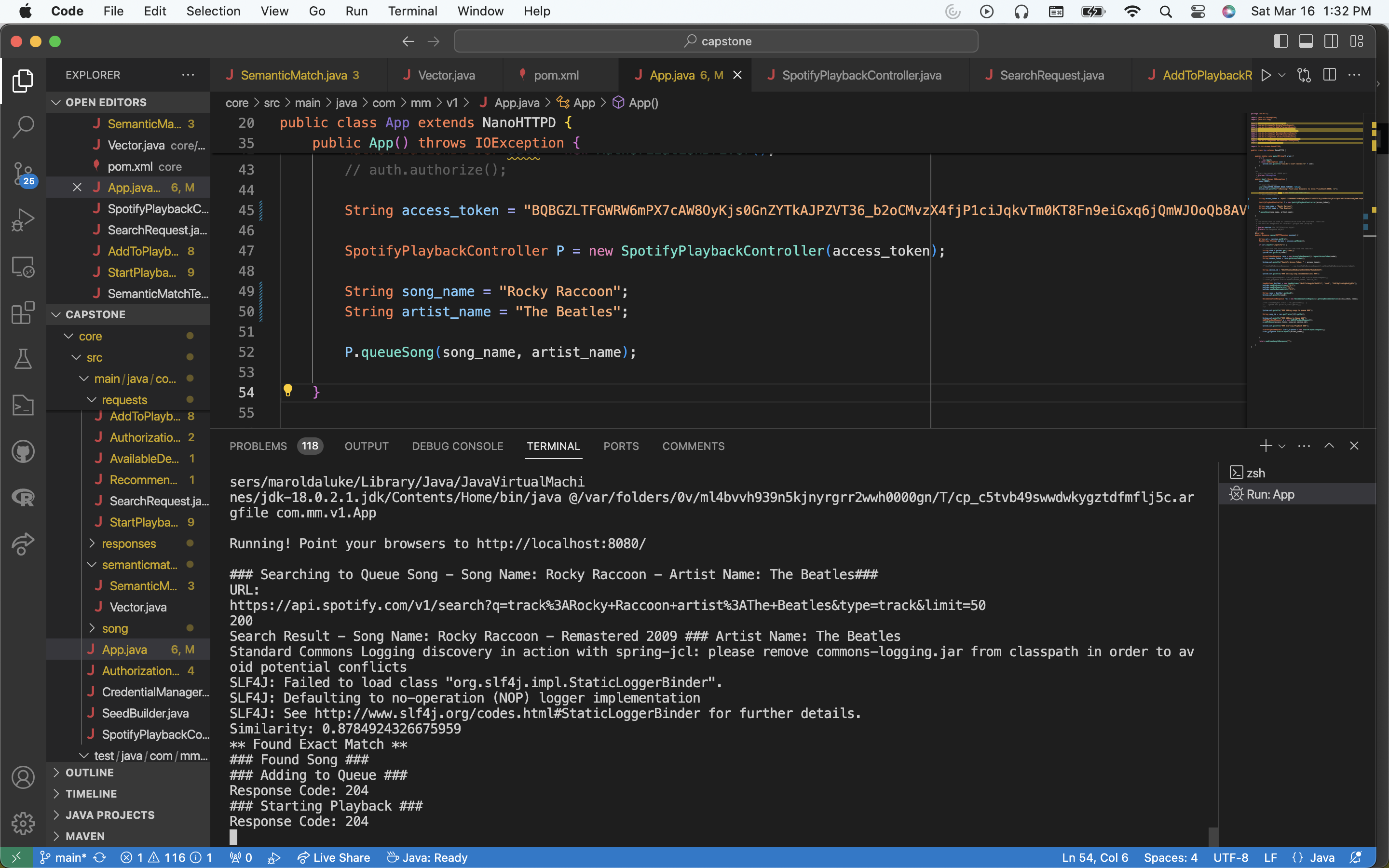
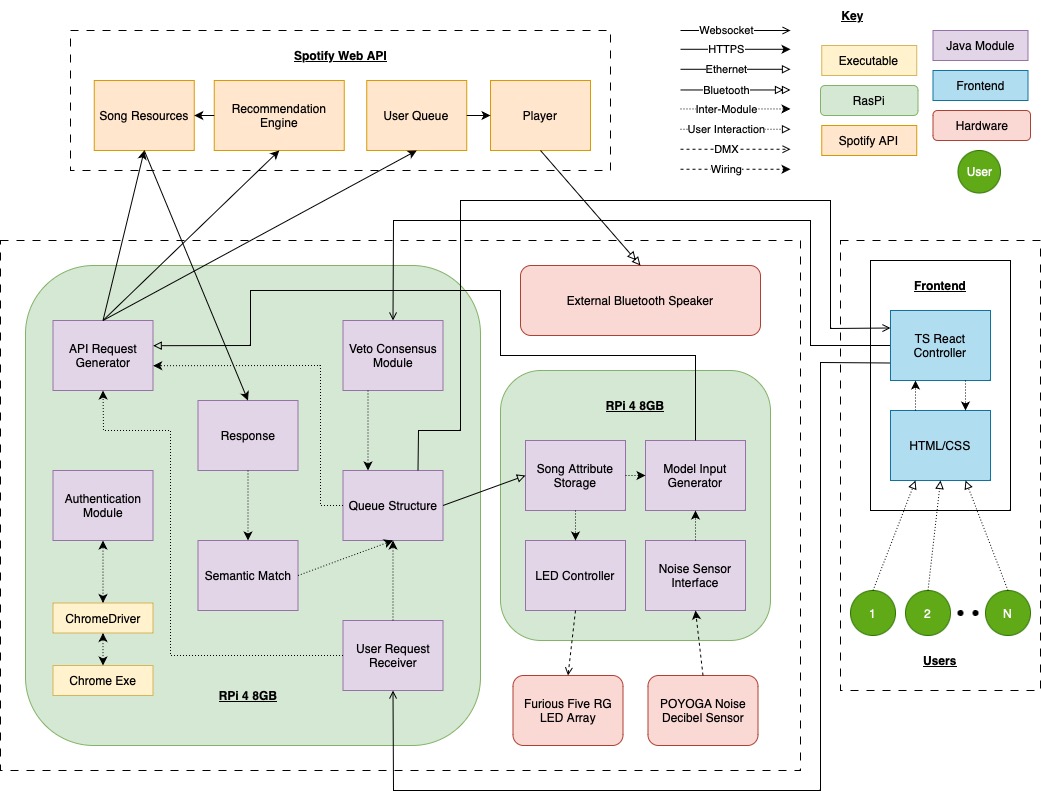
Also, note that the team as a whole did a lot of integrations together this week. We integrated the queueing and recommendation features with the actual frontend and backend internal queue components, so now Music Mirror is fully functional (an early version). You can now go on our site from multiple sessions and queue songs which are then played automatically. In fact I’m using music mirror right now as I’m writing this.
This is really good progress ahead of the demo. The next step is to continue to integrate all of these parts within the context of the broader system. Immediately, we will be integrating all of this code with the two Pis and managing the communication between the two.
In all, the team is in a good spot and this has been another great week for us in terms of progress towards our MVP.