Accomplishments
This week I accomplished one of the hard parts of the FPU job manager: writing the FSM for the Convolutional Forward module.
It’s worth mentioning that there were easier options for implementing Convolutional Forward than to define the operation in an FSM. We could have chosen to write convolutional forward in C, compile it to RISCV-assembly, and copy the code to our FPGA and use that, but this would require precious on-board memory that we need to store input samples. Writing Convolutional forward as an FSM is the fastest and smallest solution to our problem, and doing so will maximize our model throughput. Convolutional backward (gradient with respect to the inputs, filters, or bias) are essentially the same nested loops above, so implementing those operations will be significantly easier if I use the code above as a starting point.
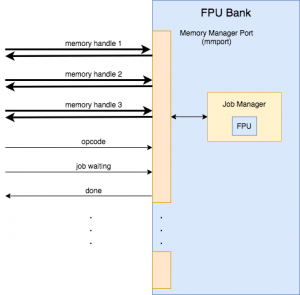
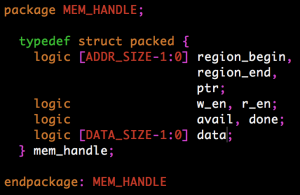
I now know the exact requirements that the FPU Job Manager needs: 32×32-bit registers that can be accessed with multiple reads and multiple writes per cycle (I will have to declare an array of registers and expose all of the wires instead of writing a Register File), and some specific ALU/FPU instructions:
- offset = channel_index + (num_channels * i) + ((num_channels * image height) * j)
- x = x + 1 (integer increment)
- x = y + z (integer addition)
- floating-point multiply
- floating-point addition
Like I mentioned last week, having Convolutional Forward completely defined will cause a lot of other pieces to fall into place. Next week, I plan on implementing some of these ALU/FPU and register requirements in SystemVerilog.
Here’s what my definition looks like:
pseudocode:
w_o_fac <- x.height * x.channels
j <- 0
j_x <- (-1 * pad)
while(j < z.width):
w_o <- w_o_fac * j_x
i <- 0
i_x <- -1 * pad
while(i < z.height):
beta <- 0
while(beta < f.width):
alpha <- 0
while(alpha <- f.height):
gamma <- 0
while(gamma < f.in_channels):
delta <- 0
while(delta < f.out_channels):
z[delta, i, j] <- z[delta, i, j] + (f[delta, gamma, alpha, beta] * x[gamma, i_x + alpha, j_x + beta])
delta <- delta + 1
gamma <- gamma + 1
alpha <- alpha + 1
beta <- beta + 1
delta <- 0
while(delta <- z.channels):
z[delta, i, j] <- z[delta, i, j] + b[delta]
delta <- delta + 1
i <- i + 1
i_x <- i_x + stride
j <- j + 1
j_x <- j_x + stride
State transitions:
// STATE == START_LOAD1
r1 <- stride
r5 <- filter.output_channels
r9 <- x.height
nextState = START_LOAD2
// STATE == START_LOAD2
r2 <- pad
r6 <- filter.input_channels
r10 <- x.width
nextState = START_LOAD3
// STATE == START_LOAD3
r3 <- output_height
r7 <- filter.height
nextState = START_LOAD4
// STATE == START_LOAD4
r4 <- output_width
r8 <- filter.width
*z <- output_height
z++
nextState = START_CALC
// STATE == START_CALC
*z <- output_width
z++
r11 <- r9 * r6 // w_o_factor = x.height * x.channels
r12 <- ~r2 + 1 // j_x = -1 * pad
r19 <- 0 // j = 0
nextState = J_LOOP
// STATE == J_LOOP
r13 <- r11 * r12
if(r19 == r4): // if j == z.width
nextState = DONE
else:
r21 <- 0 // i = 0
r20 <- ~r2 + 1 // i_x = -1 * pad
nextState = I_LOOP
// STATE == I_LOOP
if(r21 == r3): // if j == z.height
r19 <- r19 + 1 // j += 1
r12 <- r12 + r1 // j_x += stride
nextState = J_LOOP
else:
r22 <- 0 // beta = 0
r28 <- r20 * r6 // r28 = f.input_channels * i_x
nextState = BETA_LOOP
// STATE == BETA_LOOP
if(r22 == r8): // if beta == f.width
r25 <- 0 // delta = 0
z <- z - r5 // Reset z counter, we’re going to iterate over channels again
b <- 2
nextState = BIAS_LOOP_LOAD
else:
r23 <- 0 // alpha = 0
nextState = ALPHA_LOOP
// STATE == ALPHA_LOOP
if(r23 == r7): // if alpha == f.height
r22 <- r22 + 1
nextState = BETA_LOOP
else:
r24 <- 0 // gamma = 0
nextState = GAMMA_LOOP
// STATE == GAMMA_LOOP
if(r24 == r6): // if gamma == f.input_channels
r23 <- r23 + 1 // alpha = 0
nextState = ALPHA_LOOP
else:
r25 <- 0 // delta = 0
r27 <- r24 + (r6 * (r20 + r23)) + (r11 * (r12 + r22)) // x offset
nextState = DELTA_LOOP_LOAD
// STATE == DELTA_LOOP_LOAD
r14 <- *z // r14 <- z[delta, i, j]
r15 <- *f // r15 <- f[delta, gamma, alpha, beta]
r16 <- *r27 // r16 <- x[gamma, i_x + alpha, j_x + beta]
if(mem(z).done && mem(f).done && mem(x).done):
nextState = DELTA_LOOP_CALC1
else:
nextState = DELTA_LOOP_LOAD
// STATE == DELTA_LOOP_CALC1
r17 <- r15 * r16 // r17 <- f[delta, gamma, alpha, beta] * x[gamma, i_x + alpha, j_x + beta]
nextState = DELTA_LOOP_CALC2
// STATE == DELTA_LOOP_CALC2
r18 <- r14 + r17 // r18 <- z[delta, i, j] + (f[delta, gamma, alpha, beta] * x[gamma, i_x + alpha, j_x + beta])
nextState = DELTA_LOOP_STORE
// STATE == DELTA_LOOP_STORE
*z <- r18
if(mem(z).done && r25 == r5): // if(memory is done writing and delta == f.output_channels)
r24 <- r24 + 1
nextState = GAMMA_LOOP
else if(mem.done):
nextState = DELTA_LOOP_STORE
else:
r25 <- r25 + 1 // delta += 1
z++
f++
nextState = DELTA_LOOP_LOAD
// STATE == BIAS_LOOP_LOAD
r14 <- *z // r14 <- z[delta, i, j]
r15 <- *b // r15 <- b[delta]
if(mem(z).done && mem(b).done):
nextState = BIAS_LOOP_CALCS
else:
nextState = BIAS_LOOP_LOAD
// STATE == BIAS_LOOP_CALCS
r16 <- r14 + r15
nextState = BIAS_LOOP_STORE
// STATE == BIAS_LOOP_STORE
*z <- r16
if(mem(z).done && r25 == r5):
z++
b++
r21 <- r21 + 1 // i += 1
r20 <- r20 + r1 // i_x += stride
nextState = I_LOOP
else if(mem(z).done):
r25 <- r25 + 1
nextState = BIAS_LOOP_LOAD
else:
nextState = BIAS_LOOP_STORE
// STATE == DONE
Schedule
I remain on the schedule that I proposed last week.
Accomplishments for Next Week
Next week will be time to start implementing the FPU Job Manager. Now that I know the upper limit for the resources that the FPU Job Manager needs, I can be confident that I won’t have to redesign it. Although I only have a couple of FSM controllers defined, I want to go ahead with the implementation so that I can solve any unexpected problems related to SystemVerilog implementation of the modules and memory accesses.