Accomplishments
After we gave our design presentation, it became clear that we had not adequately conveyed the goal of our project. This in tandem with the fact that we did not have clearly defined overall metrics caused worry that we didn’t know why we were doing this project in the first place, which is a very fundamental perception to lack.
Our team has met about it, and we unanimously agreed that we need a solution. So for posterity, we’re writing our project goals here.
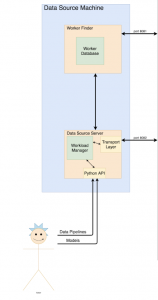
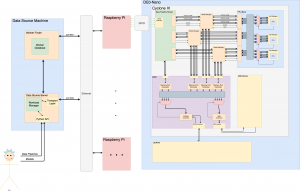
The goal of our project is to develop a system that can train a large number of machine learning models in a short amount of time at a lower price point than a GPU. This is an important problem to solve because CPU training is slow and GPU training is expensive — by building a solution with FPGAs, we can make a system that exploits data locality (by training multiple models on the same input on the same FPGA at the same time). This will decrease the time taken to train a batch of machine learning models (because training is a bus-intensive problem) and it will reduce the cost (because FPGAs are cheap).
We will measure performance with a metric that we call ”model throughput”. Model Throughput is the number of models trained from start to finish divided by the amount of time taken to train them.

We will verify our model with a written benchmark suite of models to be trained on the CIFAR10 dataset, where each individual model will fit in the 32MB SDRAM of a DE0-Nano. Currently we have 30 such models which train on two sets of features: one is full color, and the other is grayscale. The largest of these models requires about 300KB (for weights, weight gradients, and intermediate space), which fits comfortably in SDRAM.
We also measure model throughput per dollar because we want to make a system that outperforms a GPU system of the same cost. Our budget is not big enough to buy a GPU, and therefore not enough to buy a comparable FPGA setup to compare. This goes back to why model throughput is a good metric, in that it is additive. If you add a subsystem that can train 0.1 models per second to a system that can already train 1 model per second, then the total throughput of the system is 1.1 models per second. Because we judge our system by its model throughput, we can estimate the model throughput of a similar FPGA-based system that costs the same as a GPU by simply multiplying by the fraction of costs.
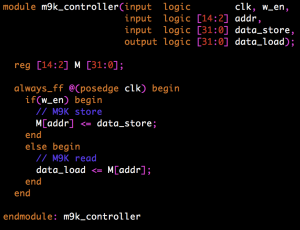
This week, we’ve also made strides in completing concrete work. TJ has put together working code for the SDRAM and M9K controllers, and Mark is close to getting a concrete number for model throughput on a CPU.
Schedule and Accomplishments for Next Week
Next week, TJ will be working on the FPU Job Manager, because that is where most of the remaining unknowns in hardware need to be figured out. SystemVerilog has the 32-bit floating-point shortreal type and several supported operations, so the most complicated part of the Job Manager will be the implementation of matrix operations and convolution.