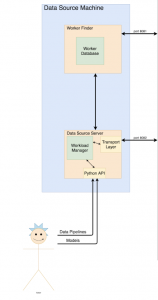
This week, I was able to setup and train 30 models on my local laptop. The hardware that I used to train was a 3.1 GHz Intel Core i5. The models were written by TJ, and using those models and a rough outline I was able to setup some code that would train each individual model, and then return some statistics. The statistics include the average time to train for the given set of models, as well as time to train the specific model as well as loss value for that model. The average time was computed by taking the time of each individual model to train, summing up all those values, and then dividing by the total # of models (30). For throughput, I decided to use minutes as the time frame as opposed to seconds, since this time scale helps better understand the speed of the CPU. Cost Effectiveness is a similar metric, except we are factoring in cost of the hardware as well.
The Statistics are as follows:
Total Time: 1588.71 seconds
Cost of CPU(3.1 GHz Intel Core i5): currently listed at $304
Average Time(Time in seconds/Total Models): 52.957 seconds per model
Throughput (Total Models/Time in Minutes): 1.13299 models per minute
Cost Effectiveness (Total Models/ (Time in Minutes x Cost of Hardware)):
0.003727 (Models/Minute Dollar)
Unfortunately, this was all I was able to accomplish this week due to external factors, meaning I am behind schedule.
In this coming week, I plan on training the same models on a different processor as well as running it on a GPU (NVIDIA 1080). I am closely working with TJ in order to help get a better understanding of some ML principles. Additionally, thanks to critique and comments from Professor Tze Meng Low, I now have a better understanding of what is expected to be included in the Design Report, as well as more insight on what potential risk factors the software side of our project could have. I also plan on adding a metric that computes the size of each model that is being trained, which will be useful for when the Workload Manager is being implemented.